Peers¶
A blockchain network is comprised primarily of a set of peer nodes (or, simply, peers). Peers are a fundamental element of the network because they host ledgers and smart contracts. Recall that a ledger immutably records all the transactions generated by smart contracts (or chaincode). Smart contracts and ledgers are used to encapsulate the shared processes and shared information in a network, respectively. These aspects of a peer make them a good starting point to understand a Hyperledger Fabric network.
Other elements of the blockchain network are of course important: ledgers and smart contracts, orderers, policies, channels, applications, organizations, identities, and membership, and you can read more about them in their own dedicated sections. This section focusses on peers, and their relationship to those other elements in a Hyperledger Fabric network.
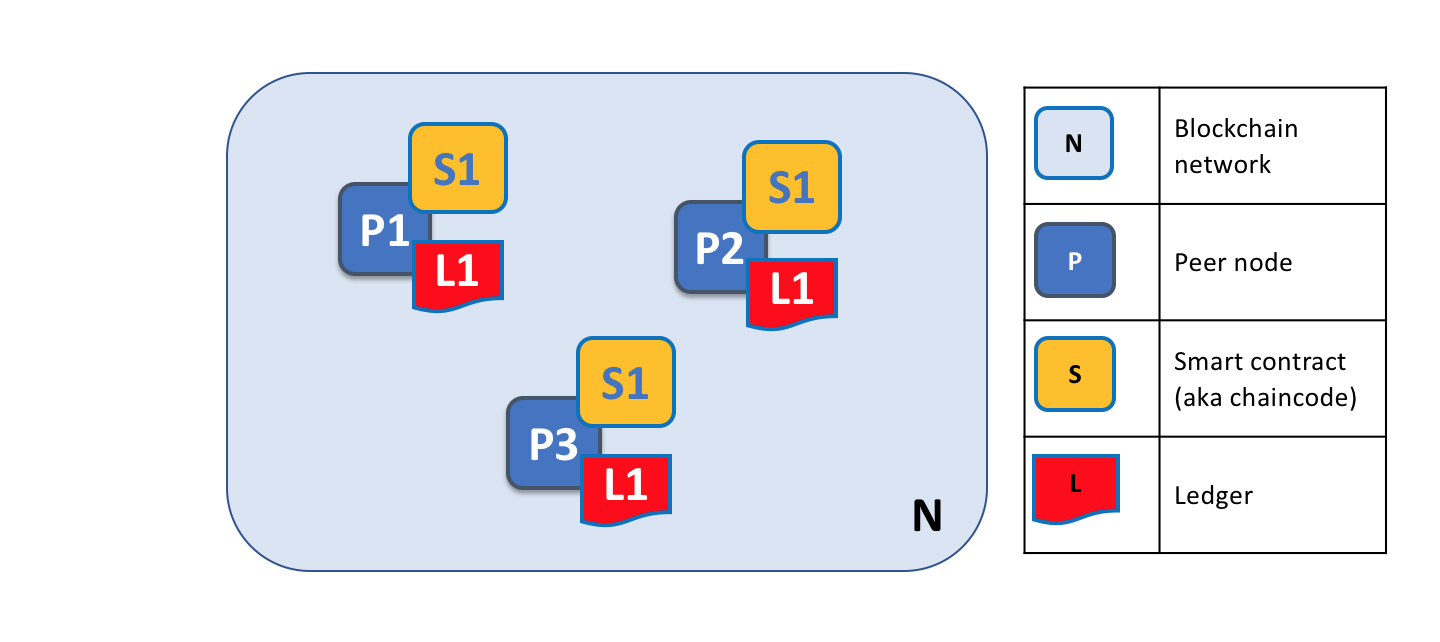
A blockchain network is comprised of peer nodes, each of which can hold copies of ledgers and copies of smart contracts. In this example, the network N consists of peers P1, P2 and P3, each of which maintain their own instance of the distributed ledger L1. P1, P2 and P3 use the same chaincode, S1, to access their copy of that distributed ledger.
Peers can be created, started, stopped, reconfigured, and even deleted. They expose a set of APIs that enable administrators and applications to interact with the services that they provide. We’ll learn more about these services in this section.
A word on terminology¶
Hyperledger Fabric implements smart contracts with a technology concept it calls chaincode — simply a piece of code that accesses the ledger, written in one of the supported programming languages. In this topic, we’ll usually use the term chaincode, but feel free to read it as smart contract if you’re more used to that term. It’s the same thing!
Ledgers and Chaincode¶
Let’s look at a peer in a little more detail. We can see that it’s the peer that hosts both the ledger and chaincode. More accurately, the peer actually hosts instances of the ledger, and instances of chaincode. Note that this provides a deliberate redundancy in a Fabric network — it avoids single points of failure. We’ll learn more about the distributed and decentralized nature of a blockchain network later in this section.
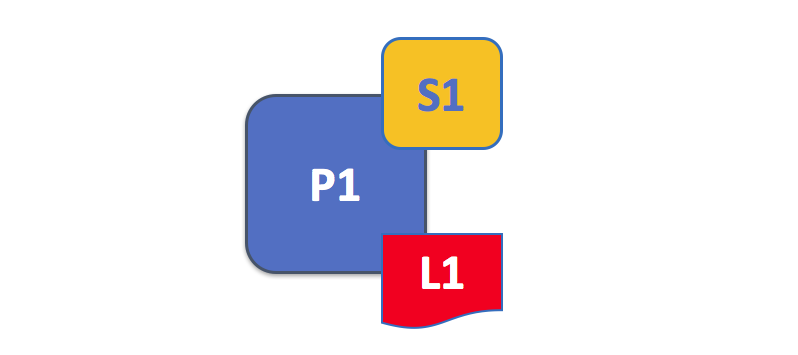
A peer hosts instances of ledgers and instances of chaincodes. In this example, P1 hosts an instance of ledger L1 and an instance of chaincode S1. There can be many ledgers and chaincodes hosted on an individual peer.
Because a peer is a host for ledgers and chaincodes, applications and administrators must interact with a peer if they want to access these resources. That’s why peers are considered the most fundamental building blocks of a Hyperledger Fabric network. When a peer is first created, it has neither ledgers nor chaincodes. We’ll see later how ledgers get created, and how chaincodes get installed, on peers.
Multiple Ledgers¶
A peer is able to host more than one ledger, which is helpful because it allows for a flexible system design. The simplest configuration is for a peer to manage a single ledger, but it’s absolutely appropriate for a peer to host two or more ledgers when required.
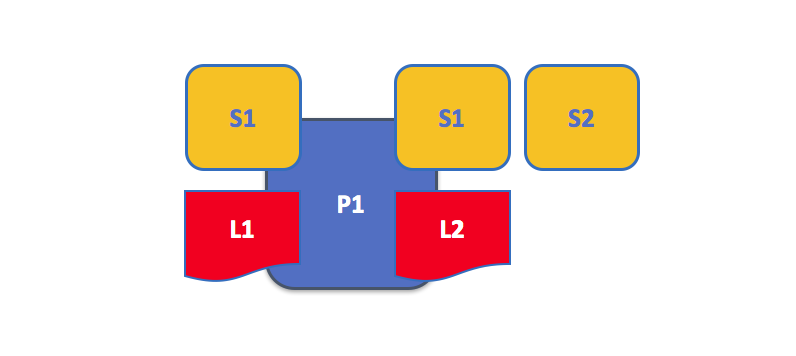
A peer hosting multiple ledgers. Peers host one or more ledgers, and each ledger has zero or more chaincodes that apply to them. In this example, we can see that the peer P1 hosts ledgers L1 and L2. Ledger L1 is accessed using chaincode S1. Ledger L2 on the other hand can be accessed using chaincodes S1 and S2.
Although it is perfectly possible for a peer to host a ledger instance without hosting any chaincodes which access that ledger, it’s rare that peers are configured this way. The vast majority of peers will have at least one chaincode installed on it which can query or update the peer’s ledger instances. It’s worth mentioning in passing that, whether or not users have installed chaincodes for use by external applications, peers also have special system chaincodes that are always present. These are not discussed in detail in this topic.
Multiple Chaincodes¶
There isn’t a fixed relationship between the number of ledgers a peer has and the number of chaincodes that can access that ledger. A peer might have many chaincodes and many ledgers available to it.
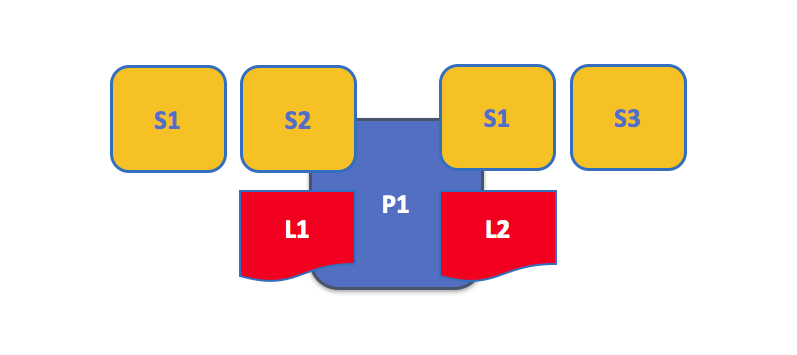
An example of a peer hosting multiple chaincodes. Each ledger can have many chaincodes which access it. In this example, we can see that peer P1 hosts ledgers L1 and L2, where L1 is accessed by chaincodes S1 and S2, and L2 is accessed by S1 and S3. We can see that S1 can access both L1 and L2.
We’ll see a little later why the concept of channels in Hyperledger Fabric is important when hosting multiple ledgers or multiple chaincodes on a peer.
Applications and Peers¶
We’re now going to show how applications interact with peers to access the ledger. Ledger-query interactions involve a simple three-step dialogue between an application and a peer; ledger-update interactions are a little more involved, and require two extra steps. We’ve simplified these steps a little to help you get started with Hyperledger Fabric, but don’t worry — what’s most important to understand is the difference in application-peer interactions for ledger-query compared to ledger-update transaction styles.
Applications always connect to peers when they need to access ledgers and chaincodes. The Hyperledger Fabric Software Development Kit (SDK) makes this easy for programmers — its APIs enable applications to connect to peers, invoke chaincodes to generate transactions, submit transactions to the network that will get ordered and committed to the distributed ledger, and receive events when this process is complete.
Through a peer connection, applications can execute chaincodes to query or update a ledger. The result of a ledger query transaction is returned immediately, whereas ledger updates involve a more complex interaction between applications, peers and orderers. Let’s investigate this in a little more detail.
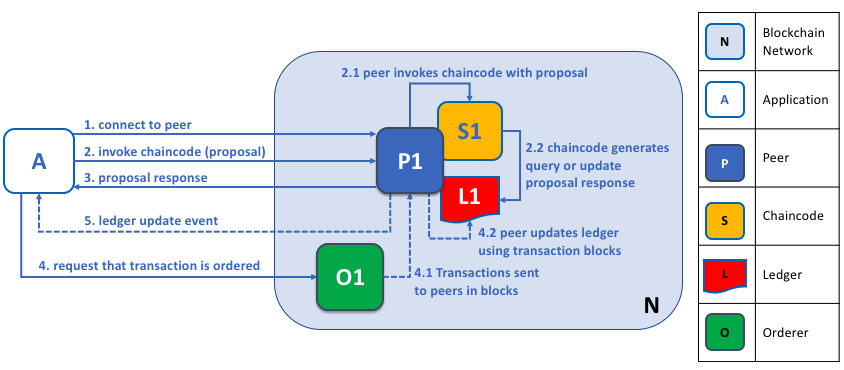
Peers, in conjunction with orderers, ensure that the ledger is kept up-to-date on every peer. In this example, application A connects to P1 and invokes chaincode S1 to query or update the ledger L1. P1 invokes S1 to generate a proposal response that contains a query result or a proposed ledger update. Application A receives the proposal response and, for queries, the process is now complete. For updates, A builds a transaction from all of the responses, which it sends it to O1 for ordering. O1 collects transactions from across the network into blocks, and distributes these to all peers, including P1. P1 validates the transaction before applying to L1. Once L1 is updated, P1 generates an event, received by A, to signify completion.
A peer can return the results of a query to an application immediately since all of the information required to satisfy the query is in the peer’s local copy of the ledger. Peers never consult with other peers in order to respond to a query from an application. Applications can, however, connect to one or more peers to issue a query; for example, to corroborate a result between multiple peers, or retrieve a more up-to-date result from a different peer if there’s a suspicion that information might be out of date. In the diagram, you can see that ledger query is a simple three-step process.
An update transaction starts in the same way as a query transaction, but has two extra steps. Although ledger-updating applications also connect to peers to invoke a chaincode, unlike with ledger-querying applications, an individual peer cannot perform a ledger update at this time, because other peers must first agree to the change — a process called consensus. Therefore, peers return to the application a proposed update — one that this peer would apply subject to other peers’ prior agreement. The first extra step — step four — requires that applications send an appropriate set of matching proposed updates to the entire network of peers as a transaction for commitment to their respective ledgers. This is achieved by the application using an orderer to package transactions into blocks, and distribute them to the entire network of peers, where they can be verified before being applied to each peer’s local copy of the ledger. As this whole ordering processing takes some time to complete (seconds), the application is notified asynchronously, as shown in step five.
Later in this section, you’ll learn more about the detailed nature of this ordering process — and for a really detailed look at this process see the Transaction Flow topic.
Peers and Channels¶
Although this section is about peers rather than channels, it’s worth spending a little time understanding how peers interact with each other, and with applications, via channels — a mechanism by which a set of components within a blockchain network can communicate and transact privately.
These components are typically peer nodes, orderer nodes and applications and, by joining a channel, they agree to collaborate to collectively share and manage identical copies of the ledger associated with that channel. Conceptually, you can think of channels as being similar to groups of friends (though the members of a channel certainly don’t need to be friends!). A person might have several groups of friends, with each group having activities they do together. These groups might be totally separate (a group of work friends as compared to a group of hobby friends), or there can be some crossover between them. Nevertheless, each group is its own entity, with “rules” of a kind.
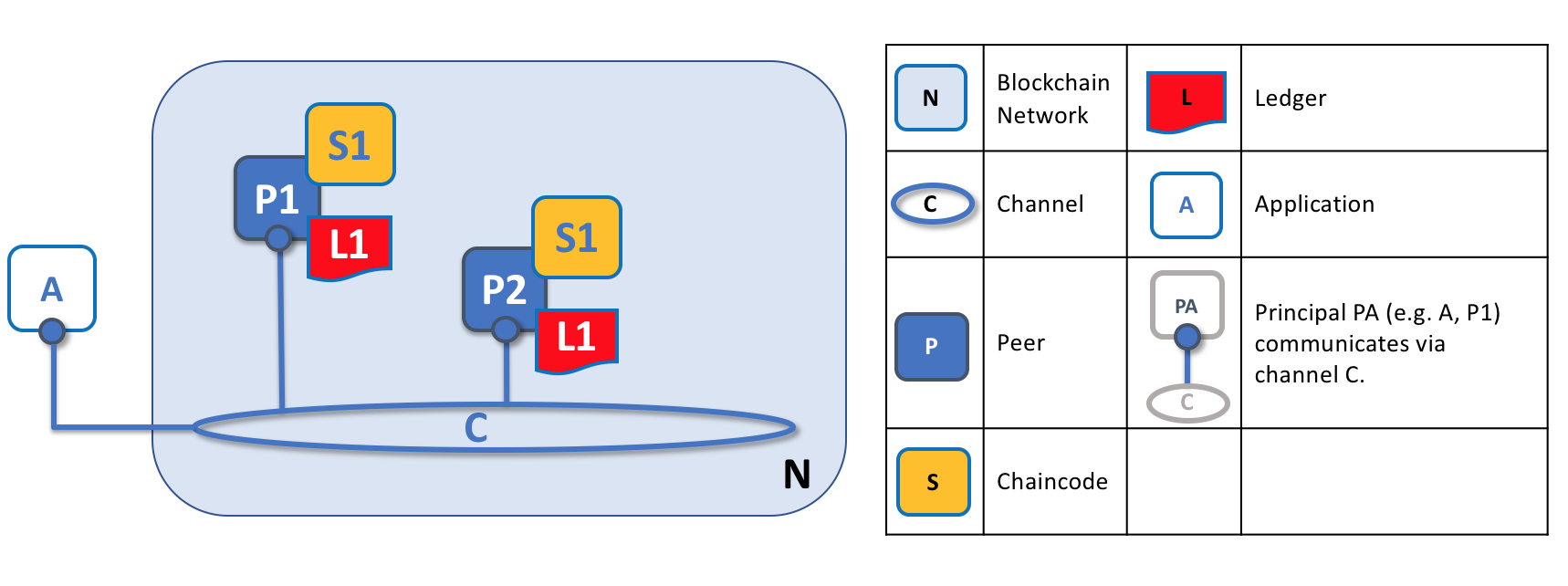
Channels allow a specific set of peers and applications to communicate with each other within a blockchain network. In this example, application A can communicate directly with peers P1 and P2 using channel C. You can think of the channel as a pathway for communications between particular applications and peers. (For simplicity, orderers are not shown in this diagram, but must be present in a functioning network.)
We see that channels don’t exist in the same way that peers do — it’s more appropriate to think of a channel as a logical structure that is formed by a collection of physical peers. It is vital to understand this point — peers provide the control point for access to, and management of, channels.
Peers and Organizations¶
Now that you understand peers and their relationship to ledgers, chaincodes and channels, you’ll be able to see how multiple organizations come together to form a blockchain network.
Blockchain networks are administered by a collection of organizations rather than a single organization. Peers are central to how this kind of distributed network is built because they are owned by — and are the connection points to the network for — these organizations.
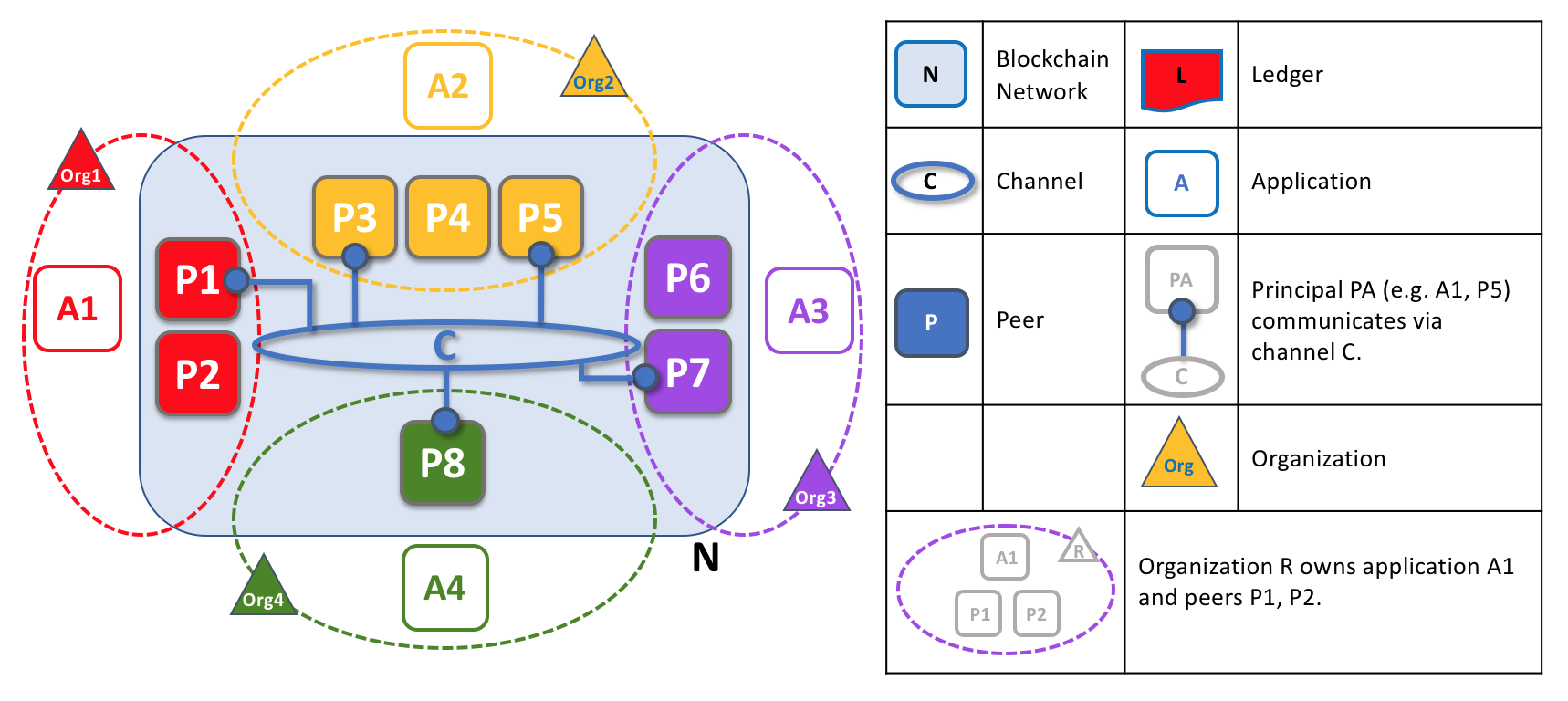
Peers in a blockchain network with multiple organizations. The blockchain network is built up from the peers owned and contributed by the different organizations. In this example, we see four organizations contributing eight peers to form a network. The channel C connects five of these peers in the network N — P1, P3, P5, P7 and P8. The other peers owned by these organizations have not been joined to this channel, but are typically joined to at least one other channel. Applications that have been developed by a particular organization will connect to their own organization’s peers as well as those of different organizations. Again, for simplicity, an orderer node is not shown in this diagram.
It’s really important that you can see what’s happening in the formation of a blockchain network. The network is both formed and managed by the multiple organizations who contribute resources to it. Peers are the resources that we’re discussing in this topic, but the resources an organization provides are more than just peers. There’s a principle at work here — the network literally does not exist without organizations contributing their individual resources to the collective network. Moreover, the network grows and shrinks with the resources that are provided by these collaborating organizations.
You can see that (other than the ordering service) there are no centralized resources — in the example above, the network, N, would not exist if the organizations did not contribute their peers. This reflects the fact that the network does not exist in any meaningful sense unless and until organizations contribute the resources that form it. Moreover, the network does not depend on any individual organization — it will continue to exist as long as one organization remains, no matter which other organizations may come and go. This is at the heart of what it means for a network to be decentralized.
Applications in different organizations, as in the example above, may or may not be the same. That’s because it’s entirely up to an organization as to how its applications process their peers’ copies of the ledger. This means that both application and presentation logic may vary from organization to organization even though their respective peers host exactly the same ledger data.
Applications connect either to peers in their organization, or peers in another organization, depending on the nature of the ledger interaction that’s required. For ledger-query interactions, applications typically connect to their own organization’s peers. For ledger-update interactions, we’ll see later why applications need to connect to peers representing every organization that is required to endorse the ledger update.
Peers and Identity¶
Now that you’ve seen how peers from different organizations come together to form a blockchain network, it’s worth spending a few moments understanding how peers get assigned to organizations by their administrators.
Peers have an identity assigned to them via a digital certificate from a particular certificate authority. You can read lots more about how X.509 digital certificates work elsewhere in this guide but, for now, think of a digital certificate as being like an ID card that provides lots of verifiable information about a peer. Each and every peer in the network is assigned a digital certificate by an administrator from its owning organization.
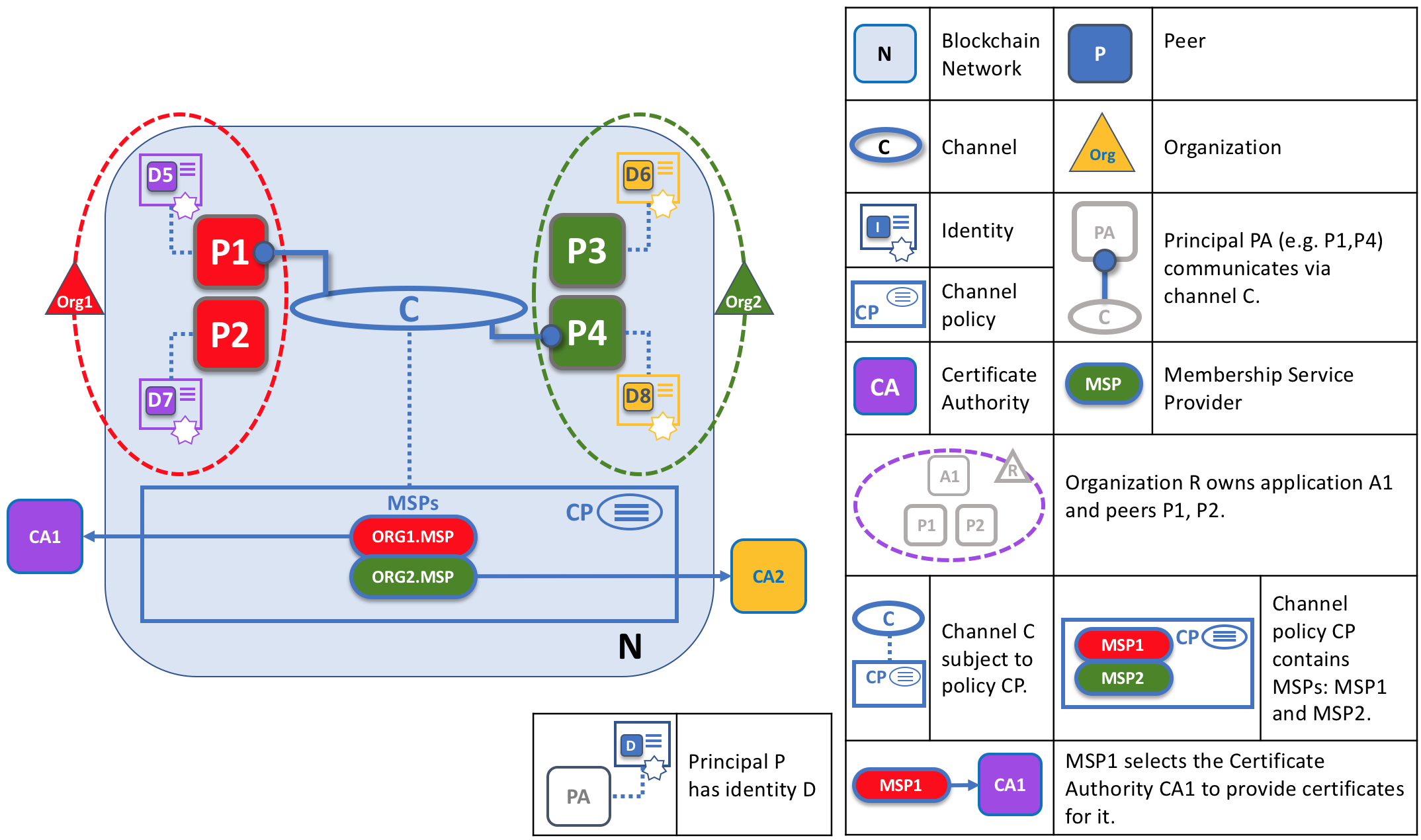
When a peer connects to a channel, its digital certificate identifies its owning organization via a channel MSP. In this example, P1 and P2 have identities issued by CA1. Channel C determines from a policy in its channel configuration that identities from CA1 should be associated with Org1 using ORG1.MSP. Similarly, P3 and P4 are identified by ORG2.MSP as being part of Org2.
Whenever a peer connects using a channel to a blockchain network, a policy in the channel configuration uses the peer’s identity to determine its rights. The mapping of identity to organization is provided by a component called a Membership Service Provider (MSP) — it determines how a peer gets assigned to a specific role in a particular organization and accordingly gains appropriate access to blockchain resources. Moreover, a peer can be owned only by a single organization, and is therefore associated with a single MSP. We’ll learn more about peer access control later in this section, and there’s an entire section on MSPs and access control policies elsewhere in this guide. But for now, think of an MSP as providing linkage between an individual identity and a particular organizational role in a blockchain network.
To digress for a moment, peers as well as everything that interacts with a blockchain network acquire their organizational identity from their digital certificate and an MSP. Peers, applications, end users, administrators and orderers must have an identity and an associated MSP if they want to interact with a blockchain network. We give a name to every entity that interacts with a blockchain network using an identity — a principal. You can learn lots more about principals and organizations elsewhere in this guide, but for now you know more than enough to continue your understanding of peers!
Finally, note that it’s not really important where the peer is physically located — it could reside in the cloud, or in a data centre owned by one of the organizations, or on a local machine — it’s the identity associated with it that identifies it as being owned by a particular organization. In our example above, P3 could be hosted in Org1’s data center, but as long as the digital certificate associated with it is issued by CA2, then it’s owned by Org2.
Peers and Orderers¶
We’ve seen that peers form the basis for a blockchain network, hosting ledgers and chaincode which can be queried and updated by peer-connected applications. However, the mechanism by which applications and peers interact with each other to ensure that every peer’s ledger is kept consistent is mediated by special nodes called orderers, and it’s to these nodes we now turn our attention.
An update transaction is quite different from a query transaction because a single peer cannot, on its own, update the ledger — updating requires the consent of other peers in the network. A peer requires other peers in the network to approve a ledger update before it can be applied to a peer’s local ledger. This process is called consensus, which takes much longer to complete than a simple query. But when all the peers required to approve the transaction do so, and the transaction is committed to the ledger, peers will notify their connected applications that the ledger has been updated. You’re about to be shown a lot more detail about how peers and orderers manage the consensus process in this section.
Specifically, applications that want to update the ledger are involved in a 3-phase process, which ensures that all the peers in a blockchain network keep their ledgers consistent with each other. In the first phase, applications work with a subset of endorsing peers, each of which provide an endorsement of the proposed ledger update to the application, but do not apply the proposed update to their copy of the ledger. In the second phase, these separate endorsements are collected together as transactions and packaged into blocks. In the final phase, these blocks are distributed back to every peer where each transaction is validated before being applied to that peer’s copy of the ledger.
As you will see, orderer nodes are central to this process, so let’s investigate in a little more detail how applications and peers use orderers to generate ledger updates that can be consistently applied to a distributed, replicated ledger.
Phase 1: Proposal¶
Phase 1 of the transaction workflow involves an interaction between an application and a set of peers — it does not involve orderers. Phase 1 is only concerned with an application asking different organizations’ endorsing peers to agree to the results of the proposed chaincode invocation.
To start phase 1, applications generate a transaction proposal which they send to each of the required set of peers for endorsement. Each of these endorsing peers then independently executes a chaincode using the transaction proposal to generate a transaction proposal response. It does not apply this update to the ledger, but rather simply signs it and returns it to the application. Once the application has received a sufficient number of signed proposal responses, the first phase of the transaction flow is complete. Let’s examine this phase in a little more detail.
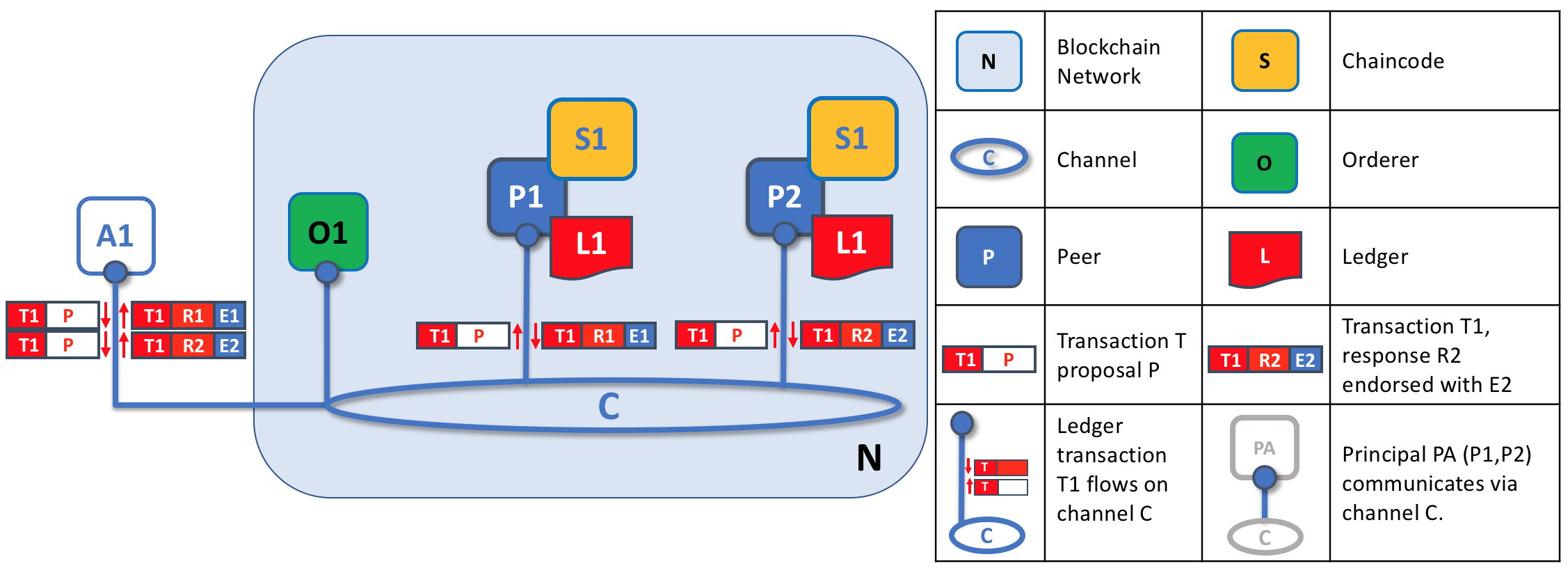
Transaction proposals are independently executed by peers who return endorsed proposal responses. In this example, application A1 generates transaction T1 proposal P which it sends to both peer P1 and peer P2 on channel C. P1 executes S1 using transaction T1 proposal P generating transaction T1 response R1 which it endorses with E1. Independently, P2 executes S1 using transaction T1 proposal P generating transaction T1 response R2 which it endorses with E2. Application A1 receives two endorsed responses for transaction T1, namely E1 and E2.
Initially, a set of peers are chosen by the application to generate a set of proposed ledger updates. Which peers are chosen by the application? Well, that depends on the endorsement policy (defined for a chaincode), which defines the set of organizations that need to endorse a proposed ledger change before it can be accepted by the network. This is literally what it means to achieve consensus — every organization who matters must have endorsed the proposed ledger change before it will be accepted onto any peer’s ledger.
A peer endorses a proposal response by adding its digital signature, and signing the entire payload using its private key. This endorsement can be subsequently used to prove that this organization’s peer generated a particular response. In our example, if peer P1 is owned by organization Org1, endorsement E1 corresponds to a digital proof that “Transaction T1 response R1 on ledger L1 has been provided by Org1’s peer P1!”.
Phase 1 ends when the application receives signed proposal responses from sufficient peers. We note that different peers can return different and therefore inconsistent transaction responses to the application for the same transaction proposal. It might simply be that the result was generated at different times on different peers with ledgers at different states, in which case an application can simply request a more up-to-date proposal response. Less likely, but much more seriously, results might be different because the chaincode is non-deterministic. Non-determinism is the enemy of chaincodes and ledgers and if it occurs it indicates a serious problem with the proposed transaction, as inconsistent results cannot, obviously, be applied to ledgers. An individual peer cannot know that their transaction result is non-deterministic — transaction responses must be gathered together for comparison before non-determinism can be detected. (Strictly speaking, even this is not enough, but we defer this discussion to the transaction section, where non-determinism is discussed in detail.)
At the end of phase 1, the application is free to discard inconsistent transaction responses if it wishes to do so, effectively terminating the transaction workflow early. We’ll see later that if an application tries to use an inconsistent set of transaction responses to update the ledger, it will be rejected.
Phase 2: Packaging¶
The second phase of the transaction workflow is the packaging phase. The orderer is pivotal to this process — it receives transactions containing endorsed transaction proposal responses from many applications. It orders each transaction relative to other transactions, and packages batches of transactions into blocks ready for distribution back to all peers connected to the orderer, including the original endorsing peers.
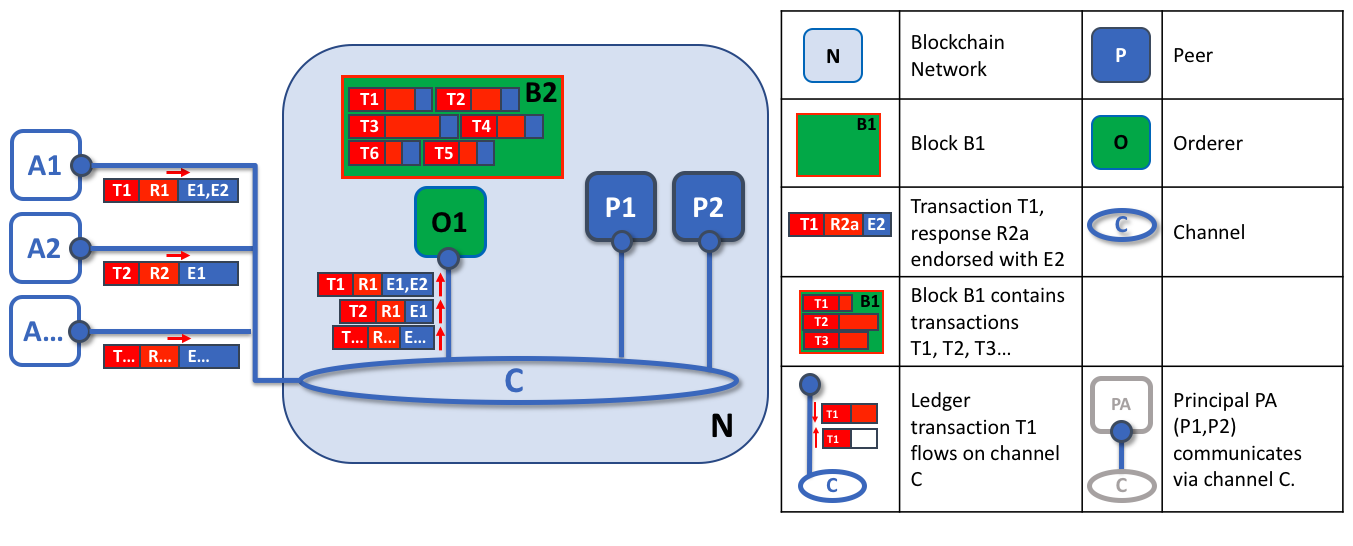
The first role of an orderer node is to package proposed ledger updates. In this example, application A1 sends a transaction T1 endorsed by E1 and E2 to the orderer O1. In parallel, Application A2 sends transaction T2 endorsed by E1 to the orderer O1. O1 packages transaction T1 from application A1 and transaction T2 from application A2 together with other transactions from other applications in the network into block B2. We can see that in B2, the transaction order is T1,T2,T3,T4,T6,T5 – which may not be the order in which these transactions arrived at the orderer node! (This example shows a very simplified orderer configuration.)
An orderer receives proposed ledger updates concurrently from many different applications in the network on a particular channel. Its job is to arrange these proposed updates into a well-defined sequence, and package them into blocks for subsequent distribution. These blocks will become the blocks of the blockchain! Once an orderer has generated a block of the desired size, or after a maximum elapsed time, it will be sent to all peers connected to it on a particular channel. We’ll see how this block is processed in phase 3.
It’s worth noting that the sequencing of transactions in a block is not necessarily the same as the order of arrival of transactions at the orderer! Transactions can be packaged in any order into a block, and it’s this sequence that becomes the order of execution. What’s important is that there is a strict order, rather than what that order is.
This strict ordering of transactions within blocks makes Hyperledger Fabric a little different from other blockchains where the same transaction can be packaged into multiple different blocks. In Hyperledger Fabric, this cannot happen — the blocks generated by a collection of orderers are said to be final because once a transaction has been written to a block, its position in the ledger is immutably assured. Hyperledger Fabric’s finality means that a disastrous occurrence known as a ledger fork cannot occur. Once transactions are captured in a block, history cannot be rewritten for that transaction at a future point in time.
We can see also see that, whereas peers host the ledger and chaincodes, orderers most definitely do not. Every transaction that arrives at an orderer is mechanically packaged in a block — the orderer makes no judgement as to the value of a transaction, it simply packages it. That’s an important property of Hyperledger Fabric — all transactions are marshalled into a strict order — transactions are never dropped or de-prioritized.
At the end of phase 2, we see that orderers have been responsible for the simple but vital processes of collecting proposed transaction updates, ordering them, packaging them into blocks, ready for distribution.
Phase 3: Validation¶
The final phase of the transaction workflow involves the distribution and subsequent validation of blocks from the orderer to the peers, where they can be applied to the ledger. Specifically, at each peer, every transaction within a block is validated to ensure that it has been consistently endorsed by all relevant organizations before it is applied to the ledger. Failed transactions are retained for audit, but are not applied to the ledger.
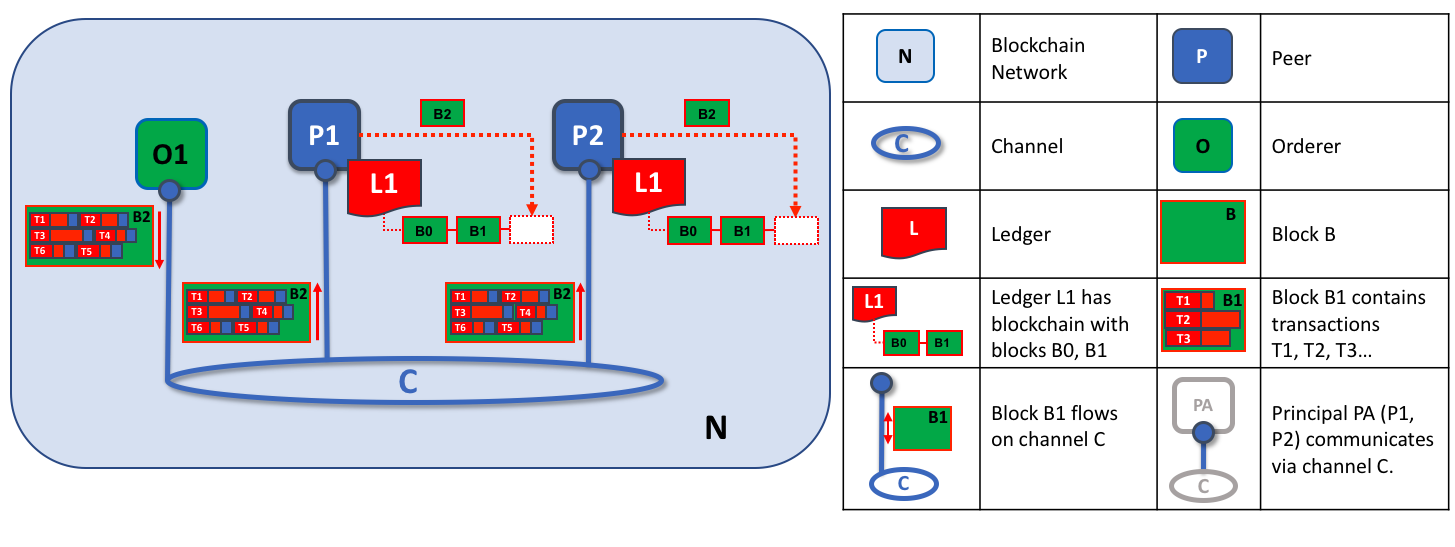
The second role of an orderer node is to distribute blocks to peers. In this example, orderer O1 distributes block B2 to peer P1 and peer P2. Peer P1 processes block B2, resulting in a new block being added to ledger L1 on P1. In parallel, peer P2 processes block B2, resulting in a new block being added to ledger L1 on P2. Once this process is complete, the ledger L1 has been consistently updated on peers P1 and P2, and each may inform connected applications that the transaction has been processed.
Phase 3 begins with the orderer distributing blocks to all peers connected to it. Peers are connected to orderers on channels such that when a new block is generated, all of the peers connected to the orderer will be sent a copy of the new block. Each peer will process this block independently, but in exactly the same way as every other peer on the channel. In this way, we’ll see that the ledger can be kept consistent. It’s also worth noting that not every peer needs to be connected to an orderer — peers can cascade blocks to other peers using the gossip protocol, who also can process them independently. But let’s leave that discussion to another time!
Upon receipt of a block, a peer will process each transaction in the sequence in which it appears in the block. For every transaction, each peer will verify that the transaction has been endorsed by the required organizations according to the endorsement policy of the chaincode which generated the transaction. For example, some transactions may only need to be endorsed by a single organization, whereas others may require multiple endorsements before they are considered valid. This process of validation verifies that all relevant organizations have generated the same outcome or result. Also note that this validation is different than the endorsement check in phase 1, where it is the application that receives the response from endorsing peers and makes the decision to send the proposal transactions. In case the application violates the endorsement policy by sending wrong transactions, the peer is still able to reject the transaction in the validation process of phase 3.
If a transaction has been endorsed correctly, the peer will attempt to apply it to the ledger. To do this, a peer must perform a ledger consistency check to verify that the current state of the ledger is compatible with the state of the ledger when the proposed update was generated. This may not always be possible, even when the transaction has been fully endorsed. For example, another transaction may have updated the same asset in the ledger such that the transaction update is no longer valid and therefore can no longer be applied. In this way each peer’s copy of the ledger is kept consistent across the network because they each follow the same rules for validation.
After a peer has successfully validated each individual transaction, it updates the ledger. Failed transactions are not applied to the ledger, but they are retained for audit purposes, as are successful transactions. This means that peer blocks are almost exactly the same as the blocks received from the orderer, except for a valid or invalid indicator on each transaction in the block.
We also note that phase 3 does not require the running of chaincodes — this is done only during phase 1, and that’s important. It means that chaincodes only have to be available on endorsing nodes, rather than throughout the blockchain network. This is often helpful as it keeps the logic of the chaincode confidential to endorsing organizations. This is in contrast to the output of the chaincodes (the transaction proposal responses) which are shared with every peer in the channel, whether or not they endorsed the transaction. This specialization of endorsing peers is designed to help scalability.
Finally, every time a block is committed to a peer’s ledger, that peer generates an appropriate event. Block events include the full block content, while block transaction events include summary information only, such as whether each transaction in the block has been validated or invalidated. Chaincode events that the chaincode execution has produced can also be published at this time. Applications can register for these event types so that they can be notified when they occur. These notifications conclude the third and final phase of the transaction workflow.
In summary, phase 3 sees the blocks which are generated by the orderer consistently applied to the ledger. The strict ordering of transactions into blocks allows each peer to validate that transaction updates are consistently applied across the blockchain network.
Orderers and Consensus¶
This entire transaction workflow process is called consensus because all peers have reached agreement on the order and content of transactions, in a process that is mediated by orderers. Consensus is a multi-step process and applications are only notified of ledger updates when the process is complete — which may happen at slightly different times on different peers.
We will discuss orderers in a lot more detail in a future orderer topic, but for now, think of orderers as nodes which collect and distribute proposed ledger updates from applications for peers to validate and include on the ledger.
That’s it! We’ve now finished our tour of peers and the other components that they relate to in Hyperledger Fabric. We’ve seen that peers are in many ways the most fundamental element — they form the network, host chaincodes and the ledger, handle transaction proposals and responses, and keep the ledger up-to-date by consistently applying transaction updates to it.