The Ordering Service¶
想定読者: アーキテクト、オーダリングサービス管理者、チャネル作成者
このトピックでは、オーダリングの概念、ordererとピアの相互作用、トランザクションフローでの役割、現在利用可能なオーダリングサービスの実装の概要について、特に推奨されるRaftオーダリングサービスの実装に重点を置いて説明します。
What is ordering?¶
EthereumやBitcoinのような多くの分散ブロックチェーンは許可型ではありません。これはどのノードも、トランザクションが順序付けられブロックに格納されるコンセンサスプロセスに参加出来るということを意味します。この事実のために、これらのシステムは、最終的には高い確率で台帳の一貫性を保証する確率的なコンセンサスアルゴリズムに依存しますが、ネットワーク内の異なる参加者が受け入れられたトランザクションの順序について別の見解を有する異なる台帳(台帳の「フォーク」としても知られる)に対しては依然として脆弱です。
Hyperledger Fabricの動作は異なります。トランザクションの順序付けを行うorderer(「オーダリングノード」とも言います)と呼ばれるノードを実装し、他のordererノードとともにオーダリングサービスを形成します。Fabricの設計は決定的なコンセンサスアルゴリズムに依存しているため、ピアによって検証されたブロックは最終的で正確であることが保証されます。他の多くの分散型で非許可型のブロックチェーンネットワークとは異なり、台帳の分岐(フォーク)は起こりません。
ファイナリティを促進することに加えて、(ピアで行われる)チェーンコードのエンドースメントの実行を、順序付けから分離することは、パフォーマンスと拡張性の点でFabricの優位性を提供し、実行と順序付けが同じノードによって行われる場合に発生する可能性があるボトルネックを排除します。
Orderer nodes and channel configuration¶
ordererは、オーダリングの役割に加えて、チャネルを作成できる組織のリストも保持します。この組織のリストは「コンソーシアム」と呼ばれ、リスト自体は「ordererシステムチャネル」(「オーダリングシステムチャネル」とも呼ばれる)の設定内に保持されます。デフォルトでは、このリストと、このリストが存在するチャネルは、ordererの管理者のみが編集できます。オーダリングサービスがこれらのリストのいくつかを保持することが可能であり、これによりコンソーシアムがFabricのマルチテナントの手段となることに留意ください。
また、ordererはチャネルに対する基本的なアクセスコントロールを実施し、チャネルに対するデータの読み取りと書き込み、およびチャネルを設定できるユーザーを制限します。チャネル内の設定要素を変更する権限を持つユーザーは、関連する管理者がコンソーシアムまたはチャネルを作成したときに設定したポリシーに従うことに注意してください。コンフィギュレーショントランザクションは、基本的なアクセス制御を実行するために現在のポリシーセットを知る必要があるため、ordererによって処理されます。この場合、ordererは設定の更新を処理して、要求者が適切な管理権限を持っていることを確認します。もし管理権限を持っていれば、ordererは既存の設定に対して更新要求を検証し、新しいコンフィギュレーショントランザクションを生成し、それをブロックにパッケージ化して、チャネル上のすべてのピアに配布します。その後、ピアはコンフィギュレーショントランザクションを処理して、ordererによってエンドースされた変更がチャネルで定義されたポリシーを実際に満たしていることを確認します。
Orderer nodes and identity¶
ピア、アプリケーション、管理者、ordererなど、ブロックチェーンネットワークとやり取りするすべてのものは、デジタル証明書とメンバーシップサービスプロバイダ(MSP)の定義から組織アイデンティティ(ID)を取得します。
アイデンティとMSPの詳細については、IdentityとMembershipに関するドキュメントを参照してください。
ピアと同様に、オーダリングノードは組織に属します。また、ピアと同様に、組織ごとに個別の認証局(CA)を使用する必要があります。このCAがルートCAとして機能するか、またはルートCAとそのルートCAに関連付けられた中間CAを展開するかはユーザ次第です。
Orderers and the transaction flow¶
Phase one: Proposal¶
私たちはPeersのトピックから、ピアがブロックチェーンネットワークの基礎を形成し、台帳をホストし、スマートコントラクトを通じてアプリケーションが台帳の内容を照会および更新できることを理解しました。
具体的には、台帳を更新するアプリケーションは、ブロックチェーンネットワーク内のすべてのピアが台帳の一貫性を維持することを保証する3つのフェーズのプロセスに関与します。
最初のフェーズでは、クライアントアプリケーションはトランザクション提案をピアのサブセットに送信します。これらのピアは、スマートコントラクトを起動して要求された台帳への更新を生成し、その結果をエンドースします。その時点では、これらエンドースメントピアは、台帳のコピーに対して更新を行いません。代わりに、エンドースメントピアはトランザクション提案への応答をクライアントアプリケーションに返します。エンドースされたトランザクション提案は、最終的にはフェーズ2でブロックの中で順序付けられ、フェーズ3で最終的な検証とコミットのためにすべてのピアに配布されます。
最初のフェーズの詳細については、Peersのトピックを参照してください。
Phase two: Ordering and packaging transactions into blocks¶
トランザクションの最初のフェーズが完了した後、クライアントアプリケーションはピア群からエンドース済のトランザクション提案へのレスポンスを受信しています。ここからトランザクションの2番目のフェーズです。
このフェーズでは、アプリケーションクライアントは、エンドース済のトランザクション提案のレスポンスを含むトランザクションをオーダーリングサービスノードに送信します。オーダリングサービスはトランザクションのブロックを作成し、最終的にはフェーズ3で最終的な検証とコミットを実施するためにチャネル上のすべてのピアに配布されます。
オーダリングサービスノードは、多くの異なるアプリケーションクライアントから同時にトランザクションを受け取ります。これらのオーダリングサービスノードは、一緒に動作して、集合的にオーダリングサービスを形成します。その役割は、サブミットされたトランザクションの集合を適切に定義された順序で配置し、それらをブロックにパッケージ化することです。これらのブロックは、ブロックチェーンのブロックになります。
ブロック内のトランザクション数は、目的のサイズおよびブロックの最大経過時間に関連するチャネル設定パラメータ(正確にはBatchSizeおよびBatchTimeoutパラメータ)によって決まります。その後、ブロックはordererの台帳に保存され、チャネルに参加している全てのピアに配布されます。この時点でピアがダウンしていたり、後からチャネルに参加した場合は、オーダリングサービスノードに再接続した後、または別のピアとゴシップ通信によりブロックを受信します。3番目のフェーズでは、このブロックがピアによってどのように処理されるかを確認します。
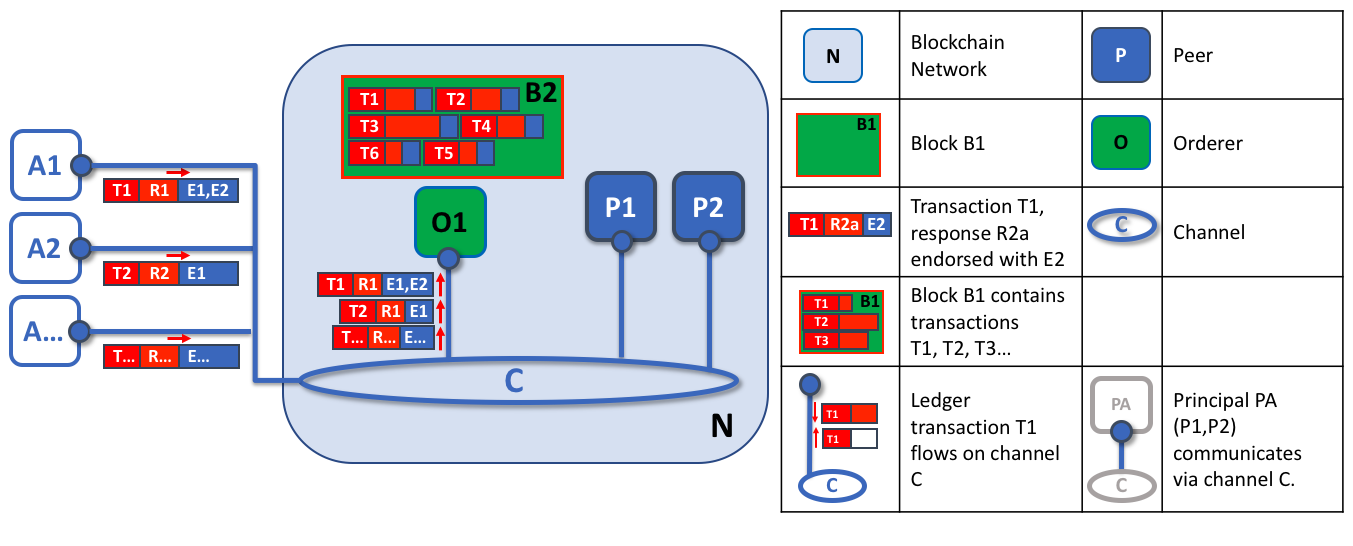
オーダリングノードの第一の役割は、提案された台帳への更新をパッケージ化することです。この例では、アプリケーションA1は、E1およびE2によってエンドースされたトランザクションT1をordererのO1に送信します。並行して、アプリケーションA2は、E1によってエンドースされたトランザクションT2をordererのO1に送信します。O1は、アプリケーションA1からのトランザクションT1とアプリケーションA2からのトランザクションT2を、ネットワーク内の他のアプリケーションからの他のトランザクションと共にブロックB2にパッケージ化します。B2では、トランザクションの順序がT1、T2、T3、T4、T6、T5であることがわかります。これは、これらトランザクションがordererに到着した順序とは異なる場合があります(この例では、オーダリングノードが1つだけの非常にシンプルなオーダリングサービス構成を示しています)。
ブロック内のトランザクションの順序は、必ずしもオーダリングサービスが受け取る順序と同じではないことに注意してください。というのも、複数のオーダリングサービスノードがほぼ同時にトランザクションを受信する可能性があるからです。重要なのは、オーダリングサービスがトランザクションを厳密な順序に並べ、ピアがトランザクションを検証およびコミットするときにこの順序を使用することです。
ブロック内のトランザクションのこの厳密な順序付けにより、Hyperledger Fabricは、同じトランザクションを複数の異なるブロックにパッケージ化してチェーンを形成することができる他のブロックチェーンとは少し異なります。Hyperledger Fabricでは、オーダリングサービスによって生成されるブロックが最終的なものです。トランザクションがブロックに書き込まれると、そのトランザクションの台帳内での位置が不変的に保証されます。前述したように、Hyperledger Fabricのファイナリティは、台帳のフォークが存在しないことを意味します。--- 検証されたトランザクションは、戻されたり削除されたりすることはありません。
また、ピアがスマートコントラクトを実行してトランザクションを処理するのに対して、ordererはそれを実行しないこともわかります。ordererに到着するすべての許可されたトランザクションは、機械的にブロックにパッケージ化されます。--- ordererは、トランザクションの内容について判断しません(前述のチャネル設定トランザクションを除く)。
フェーズ2の終わりには、提案されたトランザクションを収集し、順序付けし、ブロックにパッケージ化して配布できるようにするという、シンプルだが重要なプロセスをordererが担当していることがわかります。
Phase three: Validation and commit¶
トランザクションワークフローの3番目のフェーズでは、ブロックをordererからピアに配布して検証し、台帳にコミットします。
フェーズ3は、ordererが接続されているすべてのピアにブロックを配布することから始まります。また、すべてのピアがordererに接続する必要があるわけではありません。--- ピアはgossipプロトコルにより、他のピアにブロックを転送することができます。
各ピアは、分散されたブロックを個別に検証しますが、決定的な方法で検証し、台帳の一貫性を維持します。具体的には、チャネル内の各ピアは、ブロック内の各トランザクションを検証して、そのトランザクションが必要な組織のピアによってエンドースされていること、そのエンドースメントが一致していること、およびそのトランザクションが最初にエンドースされたときに実行中であった可能性がある他の直近のトランザクションによって無効にされていないことを確認します。無効化されたトランザクションは、ordererによって作成された不変的なブロックに保持されますが、ピアによって無効としてマークされ、台帳の状態は更新されません。
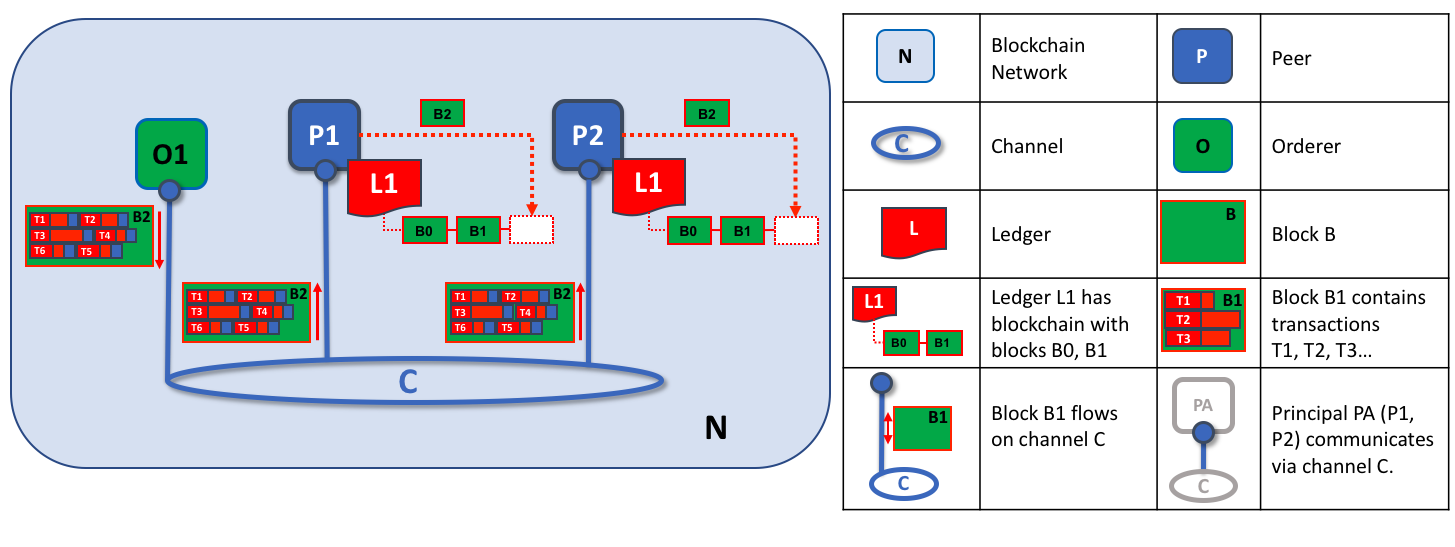
オーダリングノードの2番目の役割は、ブロックをピアに配布することです。この例では、ordererのO1はブロックB2をピアP1およびピアP2に配布します。ピアP1はブロックB2を処理し、P1の台帳L1に新しいブロックが追加されます。並行して、ピアP2はブロックB2を処理し、P2の台帳1に新しいブロックが追加されます。このプロセスが完了すると、台帳L1はピアP1およびP2上で一貫して更新され、それぞれが、トランザクションが処理されたことを接続するアプリケーションに通知することができます。
要約すると、フェーズ3では、オーダリングサービスによって生成されたブロックが一貫して台帳に適用されていることが確認されます。トランザクションをブロックに厳密に順序付けることにより、各ピアは、トランザクション更新がブロックチェーンネットワーク全体に一貫して適用されていることを検証できます。
フェーズ3の詳細については、Peersのトピックを参照してください。
Ordering service implementations¶
現在利用可能なすべてのオーダリングサービスは、トランザクションと構成の更新を同じ方法で処理しますが、オーダリングサービスノード間のトランザクションの厳密な順序付けに関する合意を達成するための実装はいくつかあります。
(ノードが使用される実装に関係なく)オーダリングノードを立てる方法については、オーダリングノードを立てるためのドキュメントを参照してください。
Raft (推奨)
v1.4.1で新しく提供されたRaftは、
etcdにおけるRaftプロトコルの実装に基づくクラッシュ故障耐性(CFT)のオーダリングサービスです。Raftは「リーダーとフォロワー」モデルに従い、リーダーノードが(チャネルごとに)選出され、その決定がフォロワーによって複製されます。Raftのオーダリングサービスは、Kafkaベースのオーダリングサービスよりもセットアップと管理が容易であり、その設計により、さまざまな組織が分散オーダリングサービスにノードを提供できるようになりました。Kafka (v2.xでは非推奨)
Raftベースのオーダリングと同様に、Apache Kafkaは「リーダーとフォロワー」のノード構成を使用するCFT実装です。KafkaはZooKeeperアンサンブルを管理目的で利用しています。KafkaベースのオーダーリングサービスはFabric v1.0から提供されていますが、多くのユーザーは、Kafkaクラスタを管理するための追加の管理オーバーヘッドを、大変で望ましくないと感じていたかもしれません。
Solo (v2.xでは非推奨)
オーダリングサービスのSolo実装はテストのみを目的としており、単一のオーダリングノードのみで構成されています。推奨されておらず、将来のリリースで完全に削除される可能性があります。Soloの既存のユーザーは、同等の機能を実装するために単一ノードのRaftネットワークに移行する必要があります。
Raft¶
Raftオーダリングサービスの設定方法については、Raftオーダリングサービスの設定に関するドキュメントを参照してください。
本番ネットワーク向けの望ましいオーダリングサービスの選択肢として、確立されたRaftプロトコルのFabric実装は、チャネル内のオーダリングノード(このノードの集合は"consent set"として知られている)の中でリーダーが動的に選出され、リーダーがメッセージをフォロワーノードに複製する"leader and follower"モデルを使用します。オーダリングノードの大部分(「クォーラム」として知られる)が残っている限り、システムは、リーダーノードを含むノードの損失に耐えることができるので、Raftは「クラッシュ故障耐性」(CFT)があると言われます。つまり、1つのチャネルに3つのノードがある場合、1つのノードの損失に耐えることができます(2つのノードが残ります)。チャネルに5つのノードがある場合、2つのノードの損失に耐えることが出来ます(残りの3つのノードで稼働します)。 Raftのこの機能は、オーダリングサービスを高可用にする戦略の一つの要素となります。さらに、本番環境では、これらのノードを複数のデータセンターあるいは場所に分散させてもよいでしょう。たとえば、3つのデータセンターにそれぞれ1つのノードを置くなどです。このようにすることで、データセンターあるいはその地域全体が利用不可能になっても、ほかのデータセンターのノードが動作し続けることができます。
ネットワークやチャネルに提供するサービスの観点からは、Raftと既存のKafkaベースのオーダリングサービス(後で説明します)は似ています。どちらもリーダーとフォロワーの構成を利用するCFTオーダリングサービスです。アプリケーション開発者、スマートコントラクト開発者、またはピア管理者であれば、RaftベースのオーダリングサービスとKafkaベースのオーダリングサービスの機能的な違いに気付くことはないでしょう。しかしながら、特にオーダリングサービスを管理する場合は、考慮すべき重要な違いがいくつかあります:
- Raftの方が構築が簡単です。Kafkaには多くのファンがいるが、彼らでさえ、KafkaクラスターとそのZooKeeperアンサンブルをデプロイするのは難しいことがあり、Kafkaのインフラと設定に高度な専門知識が必要であることをしばしば認めています。さらに、RaftよりもKafkaの方が管理すべきコンポーネントの数が多いため、問題が発生する可能性のある箇所が多くなります。Kafkaには独自のバージョンがあり、ordererのバージョンと調整する必要があります。Raftでは、すべてがオーダリングノードに組み込まれています。
- KafkaとZookeeperは、大規模なネットワークを跨いで稼働するようには設計されていません。KafkaはCFTですが、緊密なホストグループで実行する必要があります。つまり、実際には1つの組織でKafkaクラスタを実行する必要があります。そうなると、(Fabricがサポートする)Kafkaを使用する際に、異なる組織によって実行されるオーダリングノードを持つことについては、単一組織の制御下にある同じKafkaクラスタで稼働するため、分散化という点ではあまり意味がないということです。Raftを使用すると、各組織が独自のオーダリングノードを持つことができ、それぞれがオーダリングサービスに参加することで、より分散化されたシステムになります。
- Raftはネイティブにサポートされている一方で、KafkaとZookeeperについては、ユーザーは必要なイメージを自身で取得し、これらの使い方を自分で学ぶ必要があります。同様に、Kafka関連の問題へのサポートは、Hyperledger Fabricではなく、Kafkaのオープンソース開発者であるApacheを通じて対応されます。一方、Fabric Raftの実装は、Fabric開発者コミュニティとそのサポート組織の中で、開発されてきており、またサポートされます。
- Kafkaがサーバー(「Kafkaブローカー」と呼ばれる)のプールを使用し、orderer組織の管理者が特定のチャネルで使用するノードの数を指定する場合、Raftではユーザーがどのオーダリングノードをどのチャネルにデプロイするかを指定できます。このようにして、ピア組織は、ordererも所有している場合、このノードがKafkaノードを管理する中央管理者を信頼して依存するのではなく、そのチャネルのオーダリングサービスの一部になることを確実にすることができます。
- Raftは、BFT(ビザンチン故障耐性)オーダリングサービスに向けた第一歩です。これから見ていくように、Raftの開発におけるいくつかの決定は、このような方向性により行われました。BFTに興味をお持ちであれば、Raftの使い方を学ぶことで移行が容易になるはずです。
これらのすべての理由により、Fabric v2.xでは、Kafkaベースのオーダリングサービスのサポートは非推奨となっています。
注:SoloやKafkaと同様に、Raftのオーダリングサービスは、受信確認がクライアントに送信された後にトランザクションを失うことがあります。たとえば、フォロワーが受信確認を提供したとほぼ同時にリーダーがクラッシュした場合です。そのため、アプリケーションクライアントは、(トランザクションの妥当性をチェックするために)とにかくピア上でトランザクションコミットイベントをリッスンする必要がありますが、設定された時間枠内でトランザクションがコミットされないタイムアウトをクライアントが許容できるように、特別な注意を払う必要があります。アプリケーションによっては、このようなタイムアウト時にトランザクションを再送信するか、新しいエンドースメントのセットを収集することが望ましい場合があります。
Raft concepts¶
RaftはKafkaと同じ機能の多くを提供していますが --- よりシンプルで使いやすいパッケージではあります --- 振る舞いはKafkaとは根本的に異なっており、Fabricに対して多くの新しいコンセプトを導入したり、既存のコンセプトにひねりを加えたりしています。
ログエントリ。Raftオーダリングサービスにおける作業の基本単位は「ログエントリ」であり、このようなエントリの完全なシーケンスは「ログ」として知られています。ここでは、メンバーの過半数(つまりクォーラム)がエントリとその順序を承認し、さまざまなordererにログが複製されている場合に、ログの整合性が保たれていると考えます。
同意者セット。オーダリングノードは、特定のチャネルの共通メカニズムに積極的に参加し、そのチャネルの複製ログを受信します。これは、使用可能なすべてのノード(単一のクラスタまたはシステムチャネルに寄与する複数のクラスタ)、またはそれらのノードのサブセットです。
有限状態ステートマシン (FSM)。RaftのすべてのオーダリングノードはFSMを持ち、それらは集合的に、様々なオーダリングノードのログのシーケンスが決定的であることを保証するために使われます(同じシーケンスで書かれます)。
クォーラム。トランザクションを順序付けできるように、提案を確認する必要がある同意者の最小数を記述します。それぞれの同意者セットについて、これは大多数のノード数となります。5つのノードを持つクラスタでは、クォーラムを確保するためには3つのノードが使用可能である必要があります。何らかの理由でノードのクォーラムが使用できない場合、オーダリングサービスクラスタはチャネル上の読み取りと書き込み操作の両方に使用できなくなり、新しいログはコミットされません。
リーダー。これは新しい概念ではありません --- Kafkaはすでに述べたようにリーダーを使用しています --- が、チャネルの同意者セットが常に1つのノードをリーダーとして選択することを理解することは重要です(これが、Raftにおいて、これがどのように起こるかについては後で説明します)。リーダーは、新しいログエントリを取り込み、それをフォロワーノードに複製し、エントリーがコミットされたと見なされるタイミングを管理します。これは特別な種類のordererではありません。これは、ordererが特定の時点で持つことができる役割だけであり、状況によって決まる他の役割ではありません。
フォロワー。繰り返しになりますが、これは新しい概念ではありませんが、フォロワーについて理解するために重要なことは、フォロワーがリーダーからログを受信し、ログの一貫性を維持しながら決定的に複製することです。リーダー選出のセクションで説明するように、フォロワーはリーダーから「ハートビート」メッセージも受け取ります。リーダーがこれらのメッセージの送信を設定可能な時間において停止した場合、フォロワーはリーダーの選択を開始し、そのうちの1人が新しいリーダーとして選択されます。
Raft in a transaction flow¶
すべてのチャネルはRaftプロトコルの個別のインスタンス上で動作し、各インスタンスが異なるリーダーを選択できるようにします。また、この構成では、クラスタが異なる組織によって制御されるオーダリングノードで構成されている場合に、サービスをさらに分散化できます。すべてのRaftノードはシステムチャネルの一部である必要がありますが、必ずしもすべてのアプリケーションチャネルの一部である必要はありません。チャネル作成者(およびチャネル管理者)は、利用可能なordererのサブセットを選択し、必要に応じてオーダリングノードを追加または削除できます(一度に追加または削除されるノードが1つだけの場合)。
この設定では、冗長なハートビートメッセージとgoroutineの形でより多くのオーバーヘッドが発生しますが、BFTに必要な基礎が築かれます。
Raftでは、トランザクション(提案または設定更新の形式)は、トランザクションを受信するオーダリングノードによって、そのチャネルの現在のリーダーに自動的にルーティングされます。つまり、ピアやアプリケーションは、どの時点でもリーダーノードが誰であるかを知る必要はありません。オーダリングノードのみが知っていればよいということです。
Ordererの妥当性検査が完了すると、トランザクションフローのフェーズ2で説明したように、トランザクションが順序付けされ、ブロックにパッケージ化され、承諾され、配布されます。
Architectural notes¶
How leader election works in Raft¶
リーダーを選出するプロセスはordererの内部プロセスの中で行われますが、このプロセスがどのように機能するかは注目に値します。
Raftノードは常に、フォロワー(follower)、候補(candidate)、リーダー(leader)の3つの状態のいずれかになります。すべてのノードは、最初はフォロワーとして開始されます。この状態では、リーダー(選出されている場合)からログエントリを受け入れたり、リーダーに投票したりできます。設定された時間(5秒など)、ログエントリまたはハートビートを受信しなかった場合、ノードは候補の状態に自己昇格します。候補状態では、ノードは他のノードからの投票を要求します。候補者が定足数を獲得すると、リーダーに昇格します。リーダーは、新しいログエントリを受け入れて、それをフォロワーに複製する必要があります。
リーダーの選出プロセスの視覚的なイメージについては、The Secret Lives of Dataを参照ください。
Snapshots¶
オーダリングノードがダウンした場合、再起動時に失われたログはどのようにして取得されるのでしょうか。
すべてのログを無期限に保存することは可能ですが、ディスクスペースを節約するために、Raftは「スナップショット」と呼ばれるプロセスを使用しており、ログに保存するデータのバイト数をユーザーが定義できます。このデータ量は特定の数のブロックを構成します(ブロック内のデータ量に依存します。なお、スナップショットには完全なブロックのみが保存されます)。
たとえば、遅延したレプリカR1がネットワークに再接続されたとします。最新ブロックは100です。リーダーLはブロック196にあり、この場合は20ブロックを表すデータ量でスナップショットをとるように構成されます。したがって、R1は、Lからブロック180を受信し、ブロック101〜180に対してDeliverリクエストを行います。次いで、ブロック180〜196は、通常のRaftプロトコルを介してR1に複製されます。
Kafka (deprecated in v2.x)¶
Fabricがサポートするもう1つのクラッシュ故障耐性のあるオーダリングサービスは、オーダリングノードのクラスタとして使用するためのKafka分散ストリーミングプラットフォームの適用です。Apache Kafka WebサイトでKafkaの詳細を読むことができますが、KafkaはRaftと同じ概念の「リーダーとフォロワー」構成を使用しており、トランザクション(Kafkaは「メッセージ」と呼びます)はリーダーノードからフォロワーノードに複製されます。リーダーノードがダウンした場合、フォロワーの1つがリーダーになり、Raftと同様にフォールトトレランスを確保しながら順序付けを続けることができます。
Kafkaクラスタの管理(タスクの調整、クラスタメンバーシップ、アクセス制限、コントローラ選出など)は、ZooKeeperアンサンブルとその関連APIによって処理されます。
KafkaクラスタとZooKeeperのアンサンブルは設定が難しいことで知られているので、本書ではKafkaとZooKeeperの実用的な知識を前提としています。この専門知識を持たずにKafkaを使用することにした場合は、Kafkaベースのオーダリングサービスを試す前に、少なくともKafka Quickstartガイドの最初の6つのステップを完了する必要があります。また、KafkaとZooKeeperの適切なデフォルトの簡単な説明については、このサンプル設定ファイルを参照してください。
Kafkaベースのオーダリングサービスを開始する方法については、Kafkaに関する資料を参照してください。