Blockchain network¶
This topic will describe, at a conceptual level, how Hyperledger Fabric allows organizations to collaborate in the formation of blockchain networks. If you’re an architect, administrator or developer, you can use this topic to get a solid understanding of the major structure and process components in a Hyperledger Fabric blockchain network. This topic will use a manageable worked example that introduces all of the major components in a blockchain network. After understanding this example you can read more detailed information about these components elsewhere in the documentation, or try building a sample network.
After reading this topic and understanding the concept of policies, you will have a solid understanding of the decisions that organizations need to make to establish the policies that control a deployed Hyperledger Fabric network. You’ll also understand how organizations manage network evolution using declarative policies – a key feature of Hyperledger Fabric. In a nutshell, you’ll understand the major technical components of Hyperledger Fabric and the decisions organizations need to make about them.
What is a blockchain network?¶
A blockchain network is a technical infrastructure that provides ledger and smart contract (chaincode) services to applications. Primarily, smart contracts are used to generate transactions which are subsequently distributed to every peer node in the network where they are immutably recorded on their copy of the ledger. The users of applications might be end users using client applications or blockchain network administrators.
In most cases, multiple organizations come together as a consortium to form the network and their permissions are determined by a set of policies that are agreed by the consortium when the network is originally configured. Moreover, network policies can change over time subject to the agreement of the organizations in the consortium, as we’ll discover when we discuss the concept of modification policy.
The sample network¶
Before we start, let’s show you what we’re aiming at! Here’s a diagram representing the final state of our sample network.
Don’t worry that this might look complicated! As we go through this topic, we will build up the network piece by piece, so that you see how the organizations R1, R2, R3 and R4 contribute infrastructure to the network to help form it. This infrastructure implements the blockchain network, and it is governed by policies agreed by the organizations who form the network – for example, who can add new organizations. You’ll discover how applications consume the ledger and smart contract services provided by the blockchain network.
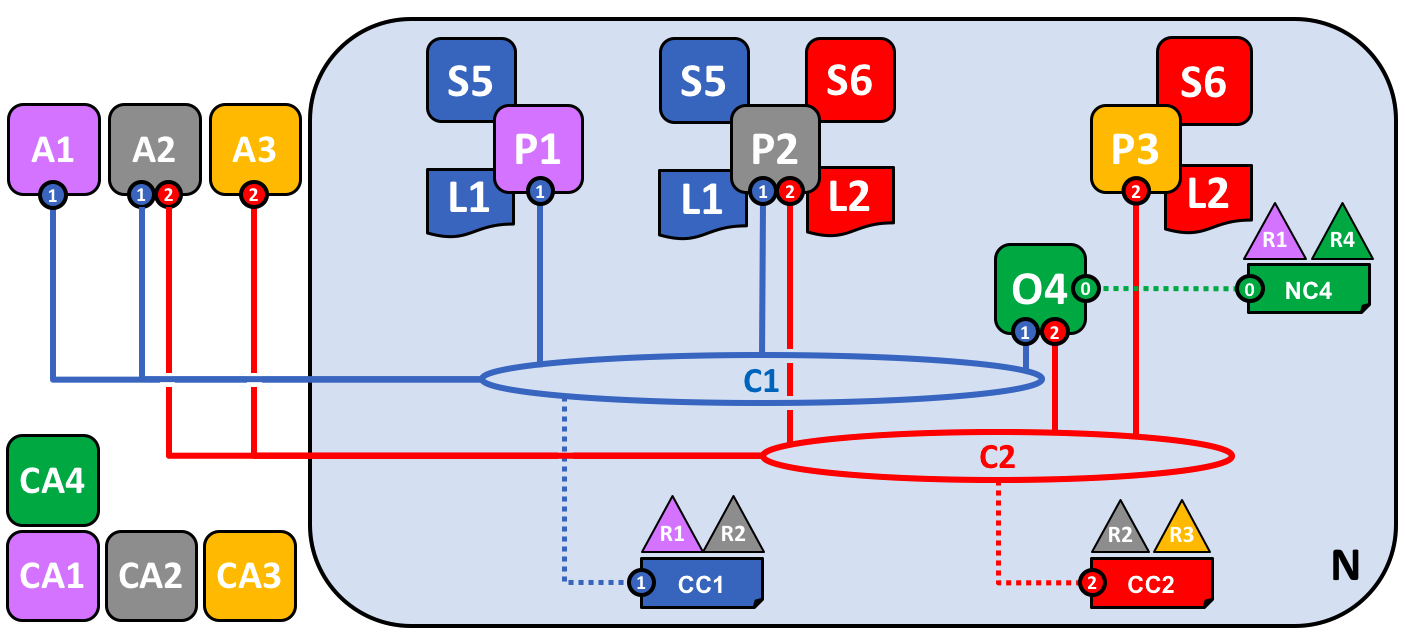
Four organizations, R1, R2, R3 and R4 have jointly decided, and written into an agreement, that they will set up and exploit a Hyperledger Fabric network. R4 has been assigned to be the network initiator – it has been given the power to set up the initial version of the network. R4 has no intention to perform business transactions on the network. R1 and R2 have a need for a private communications within the overall network, as do R2 and R3. Organization R1 has a client application that can perform business transactions within channel C1. Organization R2 has a client application that can do similar work both in channel C1 and C2. Organization R3 has a client application that can do this on channel C2. Peer node P1 maintains a copy of the ledger L1 associated with C1. Peer node P2 maintains a copy of the ledger L1 associated with C1 and a copy of ledger L2 associated with C2. Peer node P3 maintains a copy of the ledger L2 associated with C2. The network is governed according to policy rules specified in network configuration NC4, the network is under the control of organizations R1 and R4. Channel C1 is governed according to the policy rules specified in channel configuration CC1; the channel is under the control of organizations R1 and R2. Channel C2 is governed according to the policy rules specified in channel configuration CC2; the channel is under the control of organizations R2 and R3. There is an ordering service O4 that services as a network administration point for N, and uses the system channel. The ordering service also supports application channels C1 and C2, for the purposes of transaction ordering into blocks for distribution. Each of the four organizations has a preferred Certificate Authority.
Creating the Network¶
Let’s start at the beginning by creating the basis for the network:

The network is formed when an orderer is started. In our example network, N, the ordering service comprising a single node, O4, is configured according to a network configuration NC4, which gives administrative rights to organization R4. At the network level, Certificate Authority CA4 is used to dispense identities to the administrators and network nodes of the R4 organization.
We can see that the first thing that defines a network, N, is an ordering service, O4. It’s helpful to think of the ordering service as the initial administration point for the network. As agreed beforehand, O4 is initially configured and started by an administrator in organization R4, and hosted in R4. The configuration NC4 contains the policies that describe the starting set of administrative capabilities for the network. Initially this is set to only give R4 rights over the network. This will change, as we’ll see later, but for now R4 is the only member of the network.
Certificate Authorities¶
You can also see a Certificate Authority, CA4, which is used to issue certificates to administrators and network nodes. CA4 plays a key role in our network because it dispenses X.509 certificates that can be used to identify components as belonging to organization R4. Certificates issued by CAs can also be used to sign transactions to indicate that an organization endorses the transaction result – a precondition of it being accepted onto the ledger. Let’s examine these two aspects of a CA in a little more detail.
Firstly, different components of the blockchain network use certificates to identify themselves to each other as being from a particular organization. That’s why there is usually more than one CA supporting a blockchain network – different organizations often use different CAs. We’re going to use four CAs in our network; one of for each organization. Indeed, CAs are so important that Hyperledger Fabric provides you with a built-in one (called Fabric-CA) to help you get going, though in practice, organizations will choose to use their own CA.
The mapping of certificates to member organizations is achieved by via a structure called a Membership Services Provider (MSP). Network configuration NC4 uses a named MSP to identify the properties of certificates dispensed by CA4 which associate certificate holders with organization R4. NC4 can then use this MSP name in policies to grant actors from R4 particular rights over network resources. An example of such a policy is to identify the administrators in R4 who can add new member organizations to the network. We don’t show MSPs on these diagrams, as they would just clutter them up, but they are very important.
Secondly, we’ll see later how certificates issued by CAs are at the heart of the transaction generation and validation process. Specifically, X.509 certificates are used in client application transaction proposals and smart contract transaction responses to digitally sign transactions. Subsequently the network nodes who host copies of the ledger verify that transaction signatures are valid before accepting transactions onto the ledger.
Let’s recap the basic structure of our example blockchain network. There’s a resource, the network N, accessed by a set of users defined by a Certificate Authority CA4, who have a set of rights over the resources in the network N as described by policies contained inside a network configuration NC4. All of this is made real when we configure and start the ordering service node O4.
Adding Network Administrators¶
NC4 was initially configured to only allow R4 users administrative rights over the network. In this next phase, we are going to allow organization R1 users to administer the network. Let’s see how the network evolves:

Organization R4 updates the network configuration to make organization R1 an administrator too. After this point R1 and R4 have equal rights over the network configuration.
We see the addition of a new organization R1 as an administrator – R1 and R4 now have equal rights over the network. We can also see that certificate authority CA1 has been added – it can be used to identify users from the R1 organization. After this point, users from both R1 and R4 can administer the network.
Although the orderer node, O4, is running on R4’s infrastructure, R1 has shared administrative rights over it, as long as it can gain network access. It means that R1 or R4 could update the network configuration NC4 to allow the R2 organization a subset of network operations. In this way, even though R4 is running the ordering service, and R1 has full administrative rights over it, R2 has limited rights to create new consortia.
In its simplest form, the ordering service is a single node in the network, and that’s what you can see in the example. Ordering services are usually multi-node, and can be configured to have different nodes in different organizations. For example, we might run O4 in R4 and connect it to O2, a separate orderer node in organization R1. In this way, we would have a multi-site, multi-organization administration structure.
We’ll discuss the ordering service a little more later in this topic, but for now just think of the ordering service as an administration point which provides different organizations controlled access to the network.
Defining a Consortium¶
Although the network can now be administered by R1 and R4, there is very little that can be done. The first thing we need to do is define a consortium. This word literally means “a group with a shared destiny”, so it’s an appropriate choice for a set of organizations in a blockchain network.
Let’s see how a consortium is defined:

A network administrator defines a consortium X1 that contains two members, the organizations R1 and R2. This consortium definition is stored in the network configuration NC4, and will be used at the next stage of network development. CA1 and CA2 are the respective Certificate Authorities for these organizations.
Because of the way NC4 is configured, only R1 or R4 can create new consortia. This diagram shows the addition of a new consortium, X1, which defines R1 and R2 as its constituting organizations. We can also see that CA2 has been added to identify users from R2. Note that a consortium can have any number of organizational members – we have just shown two as it is the simplest configuration.
Why are consortia important? We can see that a consortium defines the set of organizations in the network who share a need to transact with one another – in this case R1 and R2. It really makes sense to group organizations together if they have a common goal, and that’s exactly what’s happening.
The network, although started by a single organization, is now controlled by a larger set of organizations. We could have started it this way, with R1, R2 and R4 having shared control, but this build up makes it easier to understand.
We’re now going to use consortium X1 to create a really important part of a Hyperledger Fabric blockchain – a channel.
Creating a channel for a consortium¶
So let’s create this key part of the Fabric blockchain network – a channel. A channel is a primary communications mechanism by which the members of a consortium can communicate with each other. There can be multiple channels in a network, but for now, we’ll start with one.
Let’s see how the first channel has been added to the network:
A channel C1 has been created for R1 and R2 using the consortium definition X1. The channel is governed by a channel configuration CC1, completely separate to the network configuration. CC1 is managed by R1 and R2 who have equal rights over C1. R4 has no rights in CC1 whatsoever.
The channel C1 provides a private communications mechanism for the consortium X1. We can see channel C1 has been connected to the ordering service O4 but that nothing else is attached to it. In the next stage of network development, we’re going to connect components such as client applications and peer nodes. But at this point, a channel represents the potential for future connectivity.
Even though channel C1 is a part of the network N, it is quite distinguishable from it. Also notice that organizations R3 and R4 are not in this channel – it is for transaction processing between R1 and R2. In the previous step, we saw how R4 could grant R1 permission to create new consortia. It’s helpful to mention that R4 also allowed R1 to create channels! In this diagram, it could have been organization R1 or R4 who created a channel C1. Again, note that a channel can have any number of organizations connected to it – we’ve shown two as it’s the simplest configuration.
Again, notice how channel C1 has a completely separate configuration, CC1, to the network configuration NC4. CC1 contains the policies that govern the rights that R1 and R2 have over the channel C1 – and as we’ve seen, R3 and R4 have no permissions in this channel. R3 and R4 can only interact with C1 if they are added by R1 or R2 to the appropriate policy in the channel configuration CC1. An example is defining who can add a new organization to the channel. Specifically, note that R4 cannot add itself to the channel C1 – it must, and can only, be authorized by R1 or R2.
Why are channels so important? Channels are useful because they provide a mechanism for private communications and private data between the members of a consortium. Channels provide privacy from other channels, and from the network. Hyperledger Fabric is powerful in this regard, as it allows organizations to share infrastructure and keep it private at the same time. There’s no contradiction here – different consortia within the network will have a need for different information and processes to be appropriately shared, and channels provide an efficient mechanism to do this. Channels provide an efficient sharing of infrastructure while maintaining data and communications privacy.
We can also see that once a channel has been created, it is in a very real sense “free from the network”. It is only organizations that are explicitly specified in a channel configuration that have any control over it, from this time forward into the future. Likewise, any updates to network configuration NC4 from this time onwards will have no direct effect on channel configuration CC1; for example if consortia definition X1 is changed, it will not affect the members of channel C1. Channels are therefore useful because they allow private communications between the organizations constituting the channel. Moreover, the data in a channel is completely isolated from the rest of the network, including other channels.
As an aside, there is also a special system channel defined for use by the ordering service. It behaves in exactly the same way as a regular channel, which are sometimes called application channels for this reason. We don’t normally need to worry about this channel, but we’ll discuss a little bit more about it later in this topic.
Peers and Ledgers¶
Let’s now start to use the channel to connect the blockchain network and the organizational components together. In the next stage of network development, we can see that our network N has just acquired two new components, namely a peer node P1 and a ledger instance, L1.
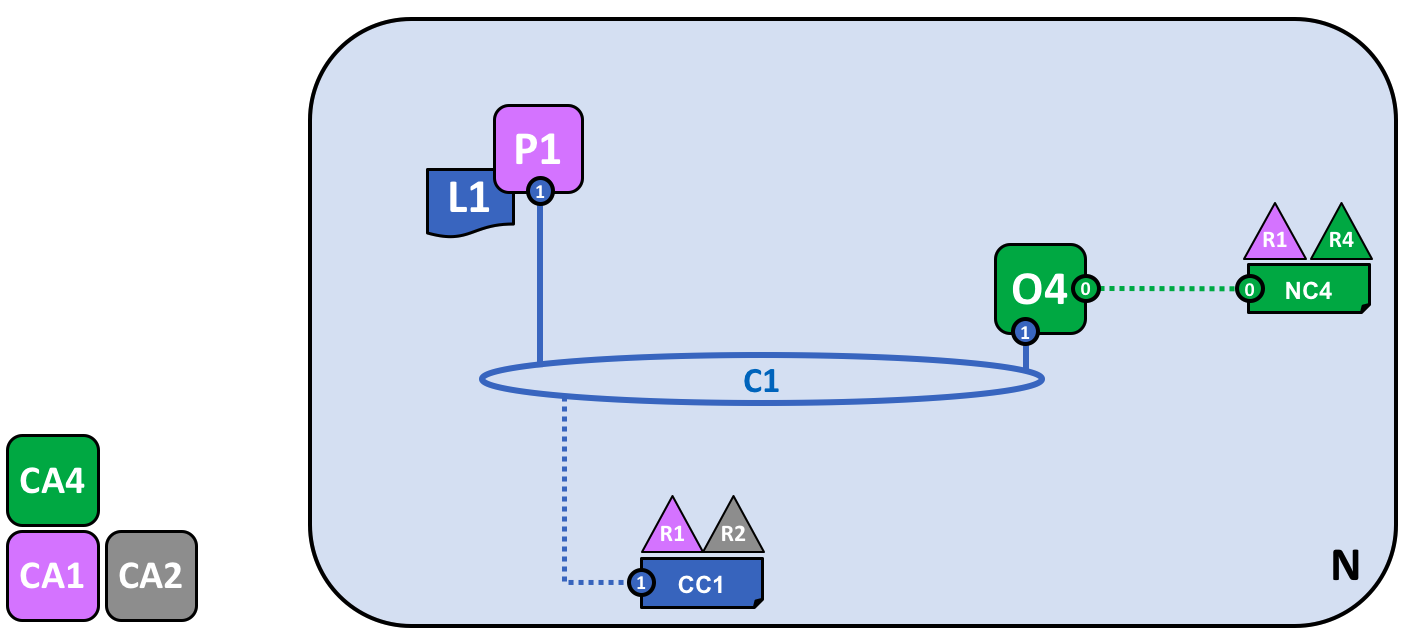
A peer node P1 has joined the channel C1. P1 physically hosts a copy of the ledger L1. P1 and O4 can communicate with each other using channel C1.
Peer nodes are the network components where copies of the blockchain ledger are hosted! At last, we’re starting to see some recognizable blockchain components! P1’s purpose in the network is purely to host a copy of the ledger L1 for others to access. We can think of L1 as being physically hosted on P1, but logically hosted on the channel C1. We’ll see this idea more clearly when we add more peers to the channel.
A key part of a P1’s configuration is an X.509 identity issued by CA1 which associates P1 with organization R1. Once P1 is started, it can join channel C1 using the orderer O4. When O4 receives this join request, it uses the channel configuration CC1 to determine P1’s permissions on this channel. For example, CC1 determines whether P1 can read and/or write information to the ledger L1.
Notice how peers are joined to channels by the organizations that own them, and though we’ve only added one peer, we’ll see how there can be multiple peer nodes on multiple channels within the network. We’ll see the different roles that peers can take on a little later.
Applications and Smart Contract chaincode¶
Now that the channel C1 has a ledger on it, we can start connecting client applications to consume some of the services provided by workhorse of the ledger, the peer!
Notice how the network has grown:
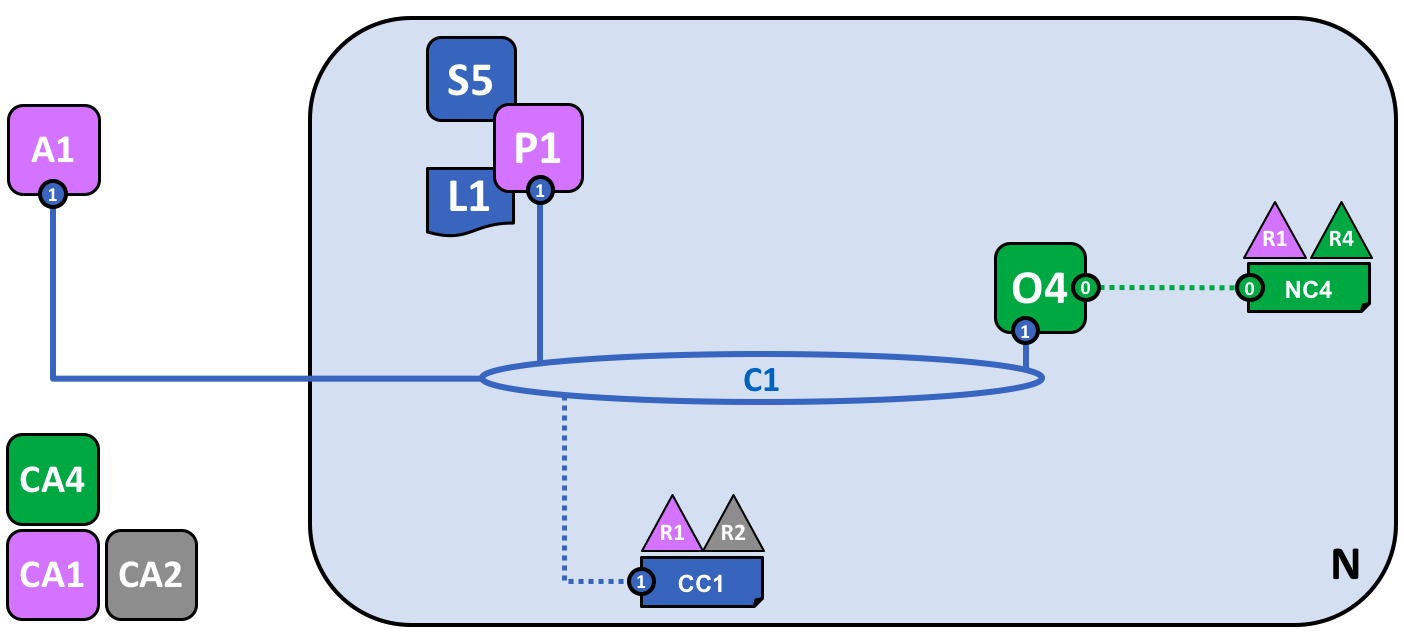
A smart contract S5 has been installed onto P1. Client application A1 in organization R1 can use S5 to access the ledger via peer node P1. A1, P1 and O4 are all joined to channel C1, i.e. they can all make use of the communication facilities provided by that channel.
In the next stage of network development, we can see that client application A1 can use channel C1 to connect to specific network resources – in this case A1 can connect to both peer node P1 and orderer node O4. Again, see how channels are central to the communication between network and organization components. Just like peers and orderers, a client application will have an identity that associates it with an organization. In our example, client application A1 is associated with organization R1; and although it is outside the Fabric blockchain network, it is connected to it via the channel C1.
It might now appear that A1 can access the ledger L1 directly via P1, but in fact, all access is managed via a special program called a smart contract chaincode, S5. Think of S5 as defining all the common access patterns to the ledger; S5 provides a well-defined set of ways by which the ledger L1 can be queried or updated. In short, client application A1 has to go through smart contract S5 to get to ledger L1!
Smart contract chaincodes can be created by application developers in each organization to implement a business process shared by the consortium members. Smart contracts are used to help generate transactions which can be subsequently distributed to the every node in the network. We’ll discuss this idea a little later; it’ll be easier to understand when the network is bigger. For now, the important thing to understand is that to get to this point two operations must have been performed on the smart contract; it must have been installed, and then instantiated.
Installing a smart contract¶
After a smart contract S5 has been developed, an administrator in organization R1 must install it onto peer node P1. This is a straightforward operation; after it has occurred, P1 has full knowledge of S5. Specifically, P1 can see the implementation logic of S5 – the program code that it uses to access the ledger L1. We contrast this to the S5 interface which merely describes the inputs and outputs of S5, without regard to its implementation.
When an organization has multiple peers in a channel, it can choose the peers upon which it installs smart contracts; it does not need to install a smart contract on every peer.
Instantiating a smart contract¶
However, just because P1 has installed S5, the other components connected to channel C1 are unaware of it; it must first be instantiated on channel C1. In our example, which only has a single peer node P1, an administrator in organization R1 must instantiate S5 on channel C1 using P1. After instantiation, every component on channel C1 is aware of the existence of S5; and in our example it means that S5 can now be invoked by client application A1!
Note that although every component on the channel can now access S5, they are not able to see its program logic. This remains private to those nodes who have installed it; in our example that means P1. Conceptually this means that it’s the smart contract interface that is instantiated, in contrast to the smart contract implementation that is installed. To reinforce this idea; installing a smart contract shows how we think of it being physically hosted on a peer, whereas instantiating a smart contract shows how we consider it logically hosted by the channel.
Endorsement policy¶
The most important piece of additional information supplied at instantiation is an endorsement policy. It describes which organizations must approve transactions before they will be accepted by other organizations onto their copy of the ledger. In our sample network, transactions can only be accepted onto ledger L1 if R1 or R2 endorse them.
The act of instantiation places the endorsement policy in channel configuration CC1; it enables it to be accessed by any member of the channel. You can read more about endorsement policies in the transaction flow topic.
Invoking a smart contract¶
Once a smart contract has been installed on a peer node and instantiated on a channel it can be invoked by a client application. Client applications do this by sending transaction proposals to peers owned by the organizations specified by the smart contract endorsement policy. The transaction proposal serves as input to the smart contract, which uses it to generate an endorsed transaction response, which is returned by the peer node to the client application.
It’s these transactions responses that are packaged together with the transaction proposal to form a fully endorsed transaction, which can be distributed to the entire network. We’ll look at this in more detail later For now, it’s enough to understand how applications invoke smart contracts to generate endorsed transactions.
By this stage in network development we can see that organization R1 is fully participating in the network. Its applications – starting with A1 – can access the ledger L1 via smart contract S5, to generate transactions that will be endorsed by R1, and therefore accepted onto the ledger because they conform to the endorsement policy.
Network completed¶
Recall that our objective was to create a channel for consortium X1 – organizations R1 and R2. This next phase of network development sees organization R2 add its infrastructure to the network.
Let’s see how the network has evolved:
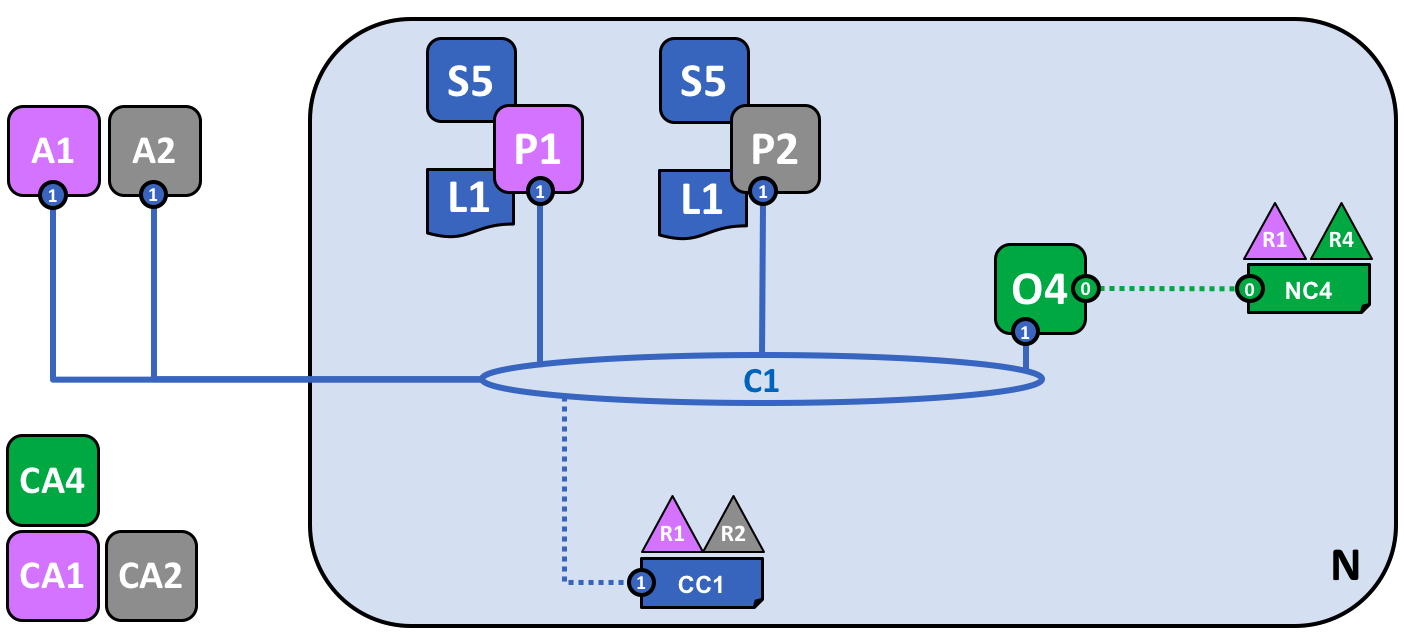
The network has grown through the addition of infrastructure from organization R2. Specifically, R2 has added peer node P2, which hosts a copy of ledger L1, and chaincode S5. P2 has also joined channel C1, as has application A2. A2 and P2 are identified using certificates from CA2. All of this means that both applications A1 and A2 can invoke S5 on C1 either using peer node P1 or P2.
We can see that organization R2 has added a peer node, P2, on channel C1. P2 also hosts a copy of the ledger L1 and smart contract S5. We can see that R2 has also added client application A2 which can connect to the network via channel C1. To achieve this, an administrator in organization R2 has created peer node P2 and joined it to channel C1, in the same way as an administrator in R1.
We have created our first operational network! At this stage in network development, we have a channel in which organizations R1 and R2 can fully transact with each other. Specifically, this means that applications A1 and A2 can generate transactions using smart contract S5 and ledger L1 on channel C1.
Generating and accepting transactions¶
In contrast to peer nodes, which always host a copy of the ledger, we see that there are two different kinds of peer nodes; those which host smart contracts and those which do not. In our network, every peer hosts a copy of the smart contract, but in larger networks, there will be many more peer nodes that do not host a copy of the smart contract. A peer can only run a smart contract if it is installed on it, but it can know about the interface of a smart contract by being connected to a channel.
You should not think of peer nodes which do not have smart contracts installed as being somehow inferior. It’s more the case that peer nodes with smart contracts have a special power – to help generate transactions. Note that all peer nodes can validate and subsequently accept or reject transactions onto their copy of the ledger L1. However, only peer nodes with a smart contract installed can take part in the process of transaction endorsement which is central to the generation of valid transactions.
We don’t need to worry about the exact details of how transactions are generated, distributed and accepted in this topic – it is sufficient to understand that we have a blockchain network where organizations R1 and R2 can share information and processes as ledger-captured transactions. We’ll learn a lot more about transactions, ledgers, smart contracts in other topics.
Types of peers¶
In Hyperledger Fabric, while all peers are the same, they can assume multiple roles depending on how the network is configured. We now have enough understanding of a typical network topology to describe these roles.
Committing peer. Every peer node in a channel is a committing peer. It receives blocks of generated transactions, which are subsequently validated before they are committed to the peer node’s copy of the ledger as an append operation.
Endorsing peer. Every peer with a smart contract can be an endorsing peer if it has a smart contract installed. However, to actually be an endorsing peer, the smart contract on the peer must be used by a client application to generate a digitally signed transaction response. The term endorsing peer is an explicit reference to this fact.
An endorsement policy for a smart contract identifies the organizations whose peer should digitally sign a generated transaction before it can be accepted onto a committing peer’s copy of the ledger.
These are the two major types of peer; there are two other roles a peer can adopt:
Leader peer. When an organization has multiple peers in a channel, a leader peer is a node which takes responsibility for distributing transactions from the orderer to the other committing peers in the organization. A peer can choose to participate in static or dynamic leadership selection.
It is helpful, therefore to think of two sets of peers from leadership perspective – those that have static leader selection, and those with dynamic leader selection. For the static set, zero or more peers can be configured as leaders. For the dynamic set, one peer will be elected leader by the set. Moreover, in the dynamic set, if a leader peer fails, then the remaining peers will re-elect a leader.
It means that an organization’s peers can have one or more leaders connected to the ordering service. This can help to improve resilience and scalability in large networks which process high volumes of transactions.
Anchor peer. If a peer needs to communicate with a peer in another organization, then it can use one of the anchor peers defined in the channel configuration for that organization. An organization can have zero or more anchor peers defined for it, and an anchor peer can help with many different cross-organization communication scenarios.
Note that a peer can be a committing peer, endorsing peer, leader peer and anchor peer all at the same time! Only the anchor peer is optional – for all practical purposes there will always be a leader peer and at least one endorsing peer and at least one committing peer.
Install not instantiate¶
In a similar way to organization R1, organization R2 must install smart contract S5 onto its peer node, P2. That’s obvious – if applications A1 or A2 wish to use S5 on peer node P2 to generate transactions, it must first be present; installation is the mechanism by which this happens. At this point, peer node P2 has a physical copy of the smart contract and the ledger; like P1, it can both generate and accept transactions onto its copy of ledger L1.
However, in contrast to organization R1, organization R2 does not need to instantiate smart contract S5 on channel C1. That’s because S5 has already been instantiated on the channel by organization R1. Instantiation only needs to happen once; any peer which subsequently joins the channel knows that smart contract S5 is available to the channel. This fact reflects the fact that ledger L1 and smart contract really exist in a physical manner on the peer nodes, and a logical manner on the channel; R2 is merely adding another physical instance of L1 and S5 to the network.
In our network, we can see that channel C1 connects two client applications, two peer nodes and an ordering service. Since there is only one channel, there is only one logical ledger with which these components interact. Peer nodes P1 and P2 have identical copies of ledger L1. Copies of smart contract S5 will usually be identically implemented using the same programming language, but if not, they must be semantically equivalent.
We can see that the careful addition of peers to the network can help support increased throughput, stability, and resilience. For example, more peers in a network will allow more applications to connect to it; and multiple peers in an organization will provide extra resilience in the case of planned or unplanned outages.
It all means that it is possible to configure sophisticated topologies which support a variety of operational goals – there is no theoretical limit to how big a network can get. Moreover, the technical mechanism by which peers within an individual organization efficiently discover and communicate with each other – the gossip protocol – will accommodate a large number of peer nodes in support of such topologies.
The careful use of network and channel policies allow even large networks to be well-governed. Organizations are free to add peer nodes to the network so long as they conform to the policies agreed by the network. Network and channel policies create the balance between autonomy and control which characterizes a de-centralized network.
Simplifying the visual vocabulary¶
We’re now going to simplify the visual vocabulary used to represent our sample blockchain network. As the size of the network grows, the lines initially used to help us understand channels will become cumbersome. Imagine how complicated our diagram would be if we added another peer or client application, or another channel?
That’s what we’re going to do in a minute, so before we do, let’s simplify the visual vocabulary. Here’s a simplified representation of the network we’ve developed so far:
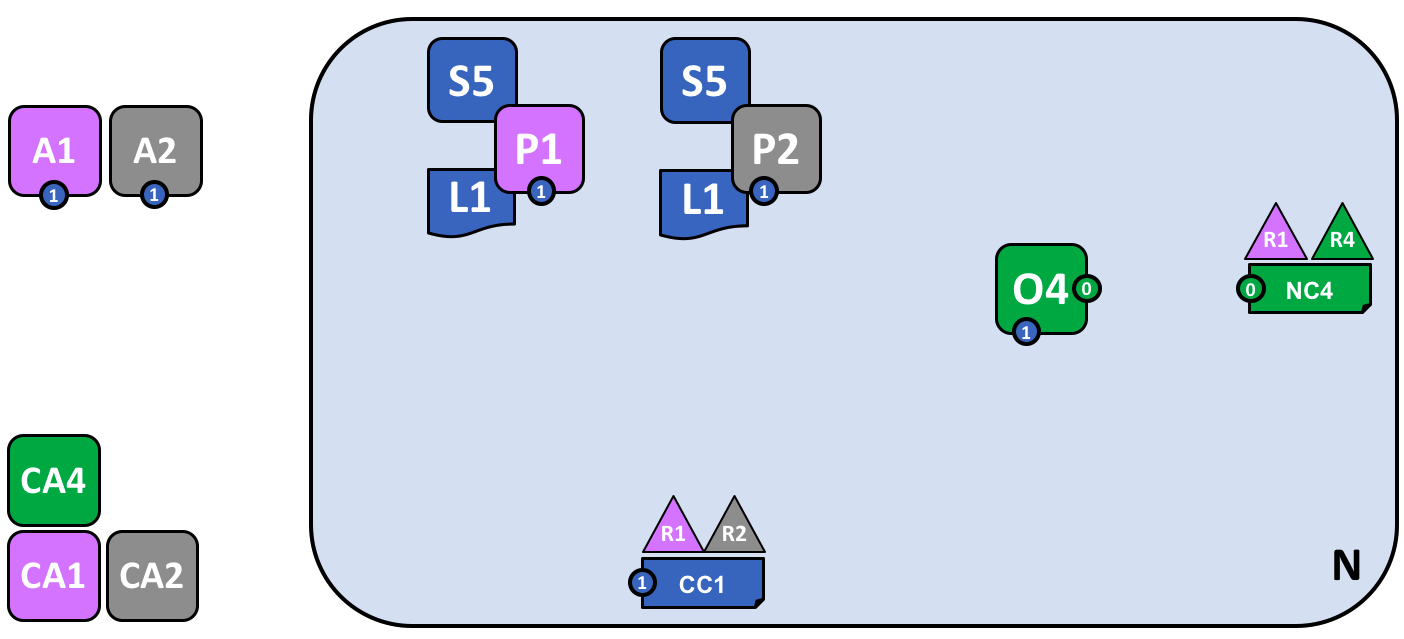
The diagram shows the facts relating to channel C1 in the network N as follows: Client applications A1 and A2 can use channel C1 for communication with peers P1 and P2, and orderer O4. Peer nodes P1 and P2 can use the communication services of channel C1. Ordering service O4 can make use of the communication services of channel C1. Channel configuration CC1 applies to channel C1.
Note that the network diagram has been simplified by replacing channel lines with connection points, shown as blue circles which include the channel number. No information has been lost. This representation is more scalable because it eliminates crossing lines. This allows us to more clearly represent larger networks. We’ve achieved this simplification by focusing on the connection points between components and a channel, rather than the channel itself.
Adding another consortium definition¶
In this next phase of network development, we introduce organization R3. We’re going to give organizations R2 and R3 a separate application channel which allows them to transact with each other. This application channel will be completely separate to that previously defined, so that R2 and R3 transactions can be kept private to them.
Let’s return to the network level and define a new consortium, X2, for R2 and R3:
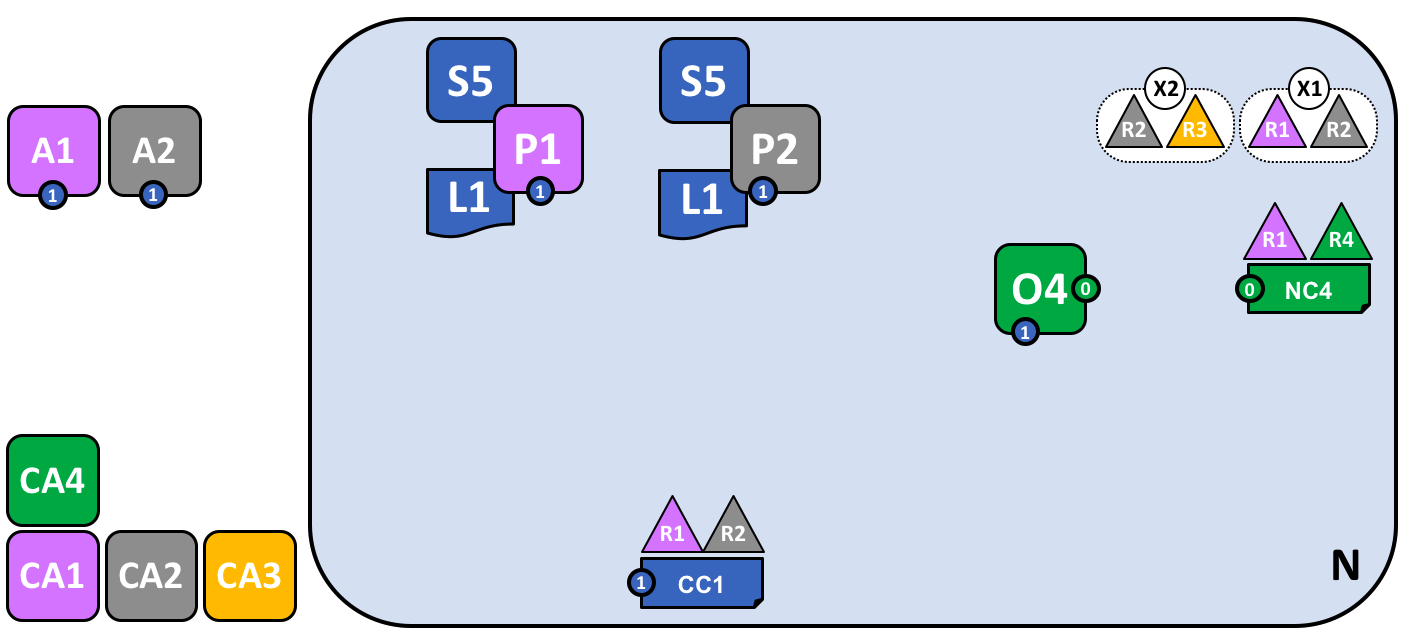
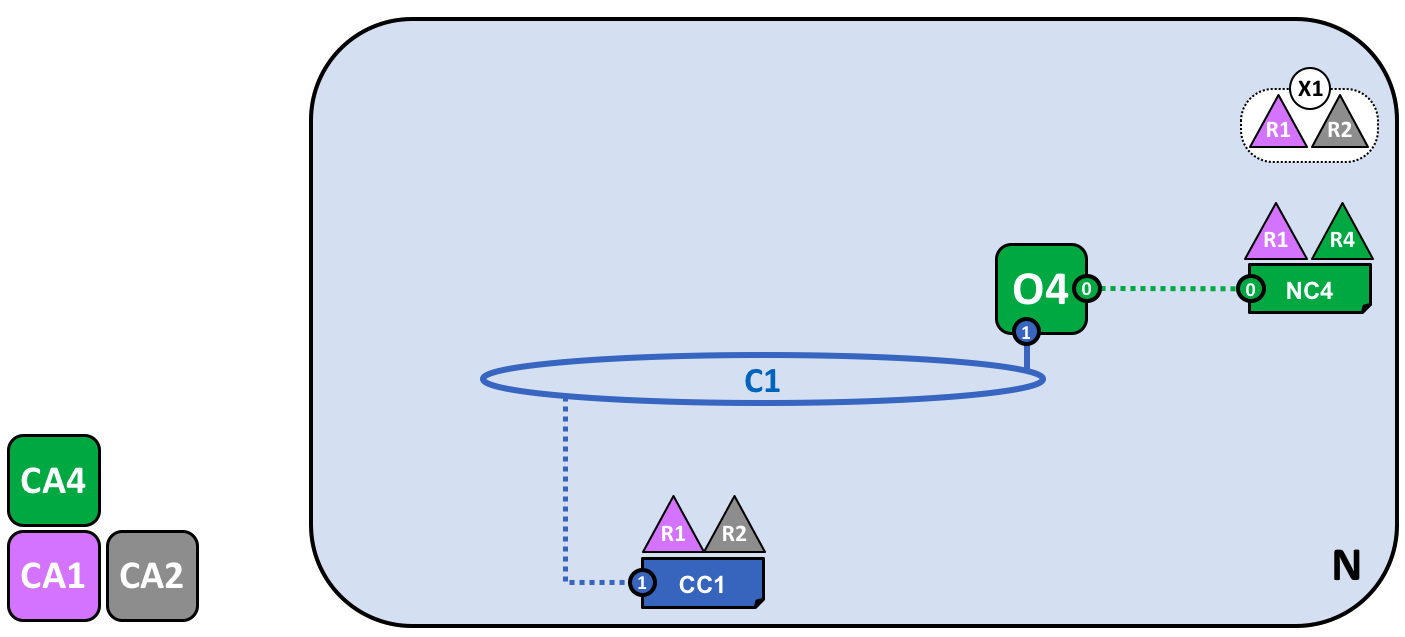
A network administrator from organization R1 or R4 has added a new consortium definition, X2, which includes organizations R2 and R3. This will be used to define a new channel for X2.
Notice that the network now has two consortia defined: X1 for organizations R1 and R2 and X2 for organizations R2 and R3. Consortium X2 has been introduced in order to be able to create a new channel for R2 and R3.
A new channel can only be created by those organizations specifically identified in the network configuration policy, NC4, as having the appropriate rights to do so, i.e. R1 or R4. This is an example of a policy which separates organizations that can manage resources at the network level versus those who can manage resources at the channel level. Seeing these policies at work helps us understand why Hyperledger Fabric has a sophisticated tiered policy structure.
In practice, consortium definition X2 has been added to the network configuration NC4. We discuss the exact mechanics of this operation elsewhere in the documentation.
Adding a new channel¶
Let’s now use this new consortium definition, X2, to create a new channel, C2. To help reinforce your understanding of the simpler channel notation, we’ve used both visual styles – channel C1 is represented with blue circular end points, whereas channel C2 is represented with red connecting lines:
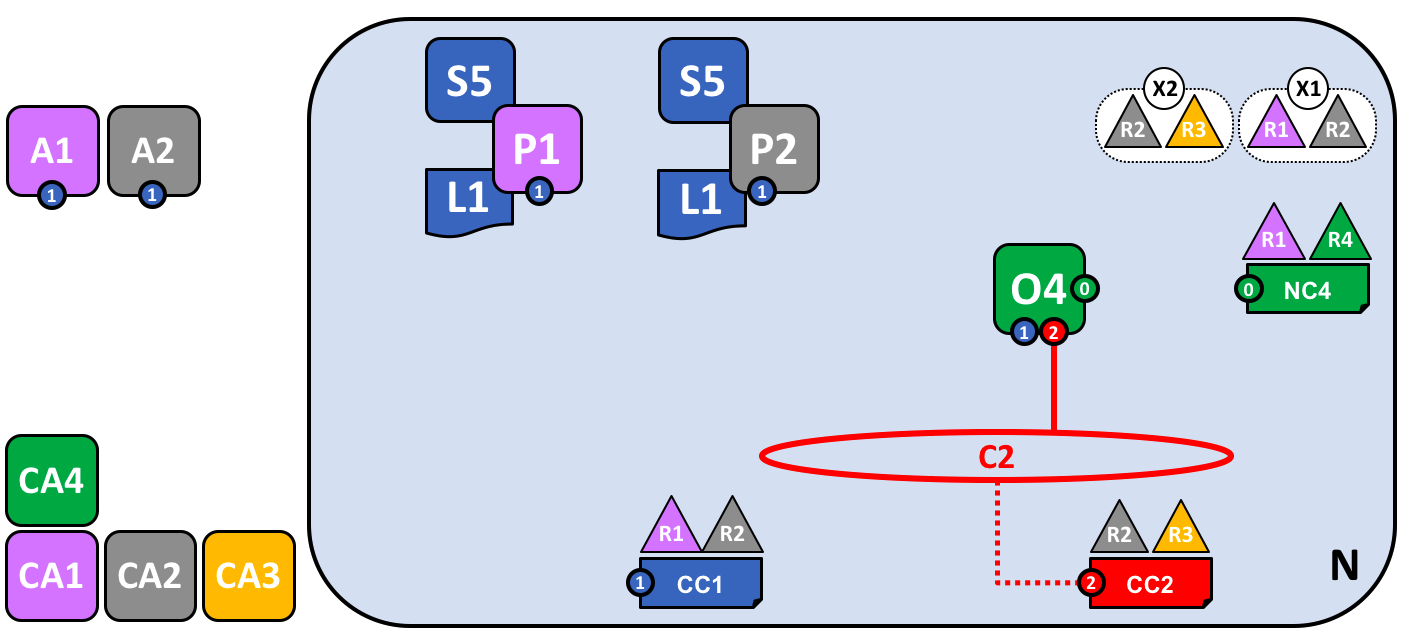
A new channel C2 has been created for R2 and R3 using consortium definition X2. The channel has a channel configuration CC2, completely separate to the network configuration NC4, and the channel configuration CC1. Channel C2 is managed by R2 and R3 who have equal rights over C2 as defined by a policy in CC2. R1 and R4 have no rights defined in CC2 whatsoever.
The channel C2 provides a private communications mechanism for the consortium X2. Again, notice how organizations united in a consortium are what form channels. The channel configuration CC2 now contains the policies that govern channel resources, assigning management rights to organizations R2 and R3 over channel C2. It is managed exclusively by R2 and R3; R1 and R4 have no power in channel C2. For example, channel configuration CC2 can subsequently be updated to add organizations to support network growth, but this can only be done by R2 or R3.
Note how the channel configurations CC1 and CC2 remain completely separate from each other, and completely separate from the network configuration, NC4. Again we’re seeing the de-centralized nature of a Hyperledger Fabric network; once channel C2 has been created, it is managed by organizations R2 and R3 independently to other network elements. Channel policies always remain separate from each other and can only be changed by the organizations authorized to do so in the channel.
As the network and channels evolve, so will the network and channel configurations. There is a process by which this is accomplished in a controlled manner – involving configuration transactions which capture the change to these configurations. Every configuration change results in a new configuration block transaction being generated, and later in this topic, we’ll see how these blocks are validated and accepted to create updated network and channel configurations respectively.
Network and channel configurations¶
Throughout our sample network, we see the importance of network and channel configurations. These configurations are important because they encapsulate the policies agreed by the network members, which provide a shared reference for controlling access to network resources. Network and channel configurations also contain facts about the network and channel composition, such as the name of consortia and its organizations.
For example, when the network is first formed using the ordering service node O4, its behaviour is governed by the network configuration NC4. The initial configuration of NC4 only contains policies that permit organization R4 to manage network resources. NC4 is subsequently updated to also allow R1 to manage network resources. Once this change is made, any administrator from organization R1 or R4 that connects to O4 will have network management rights because that is what the policy in the network configuration NC4 permits. Internally, each node in the ordering service records each channel in the network configuration, so that there is a record of each channel created, at the network level.
It means that although ordering service node O4 is the actor that created consortia X1 and X2 and channels C1 and C2, the intelligence of the network is contained in the network configuration NC4 that O4 is obeying. As long as O4 behaves as a good actor, and correctly implements the policies defined in NC4 whenever it is dealing with network resources, our network will behave as all organizations have agreed. In many ways NC4 can be considered more important than O4 because, ultimately, it controls network access.
The same principles apply for channel configurations with respect to peers. In our network, P1 and P2 are likewise good actors. When peer nodes P1 and P2 are interacting with client applications A1 or A2 they are each using the policies defined within channel configuration CC1 to control access to the channel C1 resources.
For example, if A1 wants to access the smart contract chaincode S5 on peer nodes P1 or P2, each peer node uses its copy of CC1 to determine the operations that A1 can perform. For example, A1 may be permitted to read or write data from the ledger L1 according to policies defined in CC1. We’ll see later the same pattern for actors in channel and its channel configuration CC2. Again, we can see that while the peers and applications are critical actors in the network, their behaviour in a channel is dictated more by the channel configuration policy than any other factor.
Finally, it is helpful to understand how network and channel configurations are physically realized. We can see that network and channel configurations are logically singular – there is one for the network, and one for each channel. This is important; every component that accesses the network or the channel must have a shared understanding of the permissions granted to different organizations.
Even though there is logically a single configuration, it is actually replicated and kept consistent by every node that forms the network or channel. For example, in our network peer nodes P1 and P2 both have a copy of channel configuration CC1, and by the time the network is fully complete, peer nodes P2 and P3 will both have a copy of channel configuration CC2. Similarly ordering service node O4 has a copy of the network configuration, but in a multi-node configuration, every ordering service node will have its own copy of the network configuration.
Both network and channel configurations are kept consistent using the same blockchain technology that is used for user transactions – but for configuration transactions. To change a network or channel configuration, an administrator must submit a configuration transaction to change the network or channel configuration. It must be signed by the organizations identified in the appropriate policy as being responsible for configuration change. This policy is called the mod_policy and we’ll discuss it later.
Indeed, the ordering service nodes operate a mini-blockchain, connected via the system channel we mentioned earlier. Using the system channel ordering service nodes distribute network configuration transactions. These transactions are used to co-operatively maintain a consistent copy of the network configuration at each ordering service node. In a similar way, peer nodes in an application channel can distribute channel configuration transactions. Likewise, these transactions are used to maintain a consistent copy of the channel configuration at each peer node.
This balance between objects that are logically singular, by being physically distributed is a common pattern in Hyperledger Fabric. Objects like network configurations, that are logically single, turn out to be physically replicated among a set of ordering services nodes for example. We also see it with channel configurations, ledgers, and to some extent smart contracts which are installed in multiple places but whose interfaces exist logically at the channel level. It’s a pattern you see repeated time and again in Hyperledger Fabric, and enables Hyperledger Fabric to be both de-centralized and yet manageable at the same time.
Adding another peer¶
Now that organization R3 is able to fully participate in channel C2, let’s add its infrastructure components to the channel. Rather than do this one component at a time, we’re going to add a peer, its local copy of a ledger, a smart contract and a client application all at once!
Let’s see the network with organization R3’s components added:
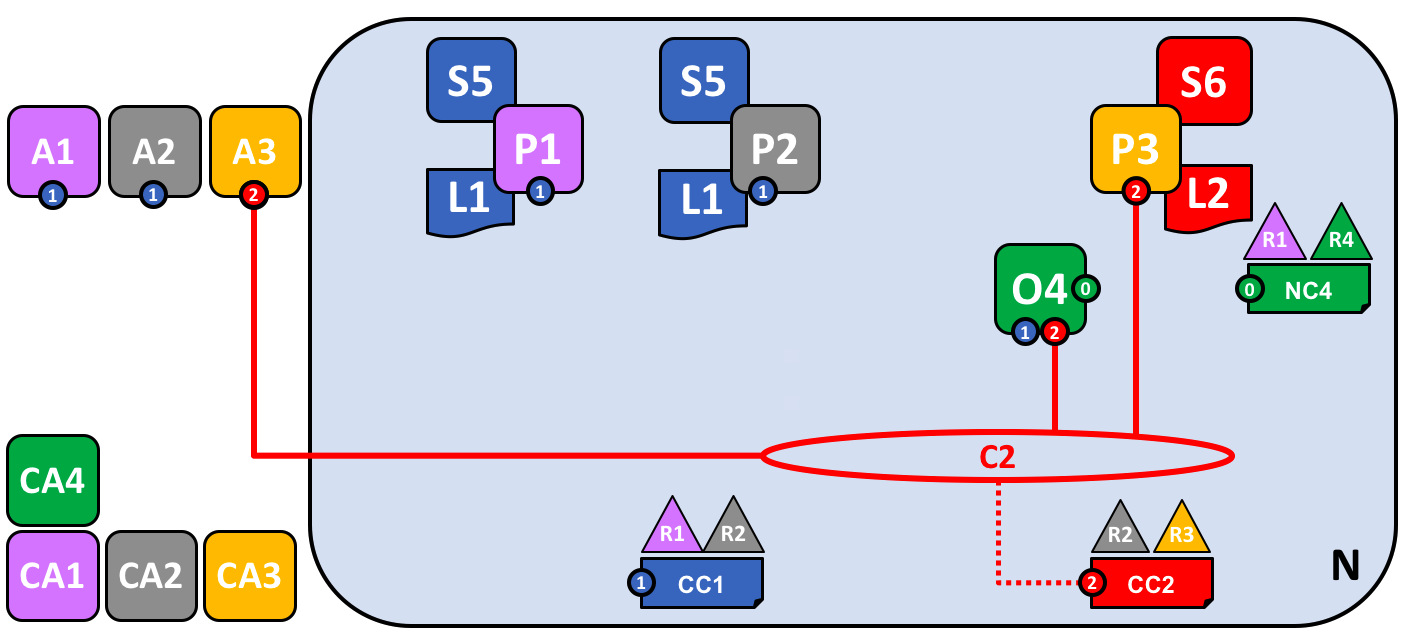
The diagram shows the facts relating to channels C1 and C2 in the network N as follows: Client applications A1 and A2 can use channel C1 for communication with peers P1 and P2, and ordering service O4; client applications A3 can use channel C2 for communication with peer P3 and ordering service O4. Ordering service O4 can make use of the communication services of channels C1 and C2. Channel configuration CC1 applies to channel C1, CC2 applies to channel C2.
First of all, notice that because peer node P3 is connected to channel C2, it has a different ledger – L2 – to those peer nodes using channel C1. The ledger L2 is effectively scoped to channel C2. The ledger L1 is completely separate; it is scoped to channel C1. This makes sense – the purpose of the channel C2 is to provide private communications between the members of the consortium X2, and the ledger L2 is the private store for their transactions.
In a similar way, the smart contract S6, installed on peer node P3, and instantiated on channel C2, is used to provide controlled access to ledger L2. Application A3 can now use channel C2 to invoke the services provided by smart contract S6 to generate transactions that can be accepted onto every copy of the ledger L2 in the network.
At this point in time, we have a single network that has two completely separate channels defined within it. These channels provide independently managed facilities for organizations to transact with each other. Again, this is de-centralization at work; we have a balance between control and autonomy. This is achieved through policies which are applied to channels which are controlled by, and affect, different organizations.
Joining a peer to multiple channels¶
In this final stage of network development, let’s return our focus to organization R2. We can exploit the fact that R2 is a member of both consortia X1 and X2 by joining it to multiple channels:
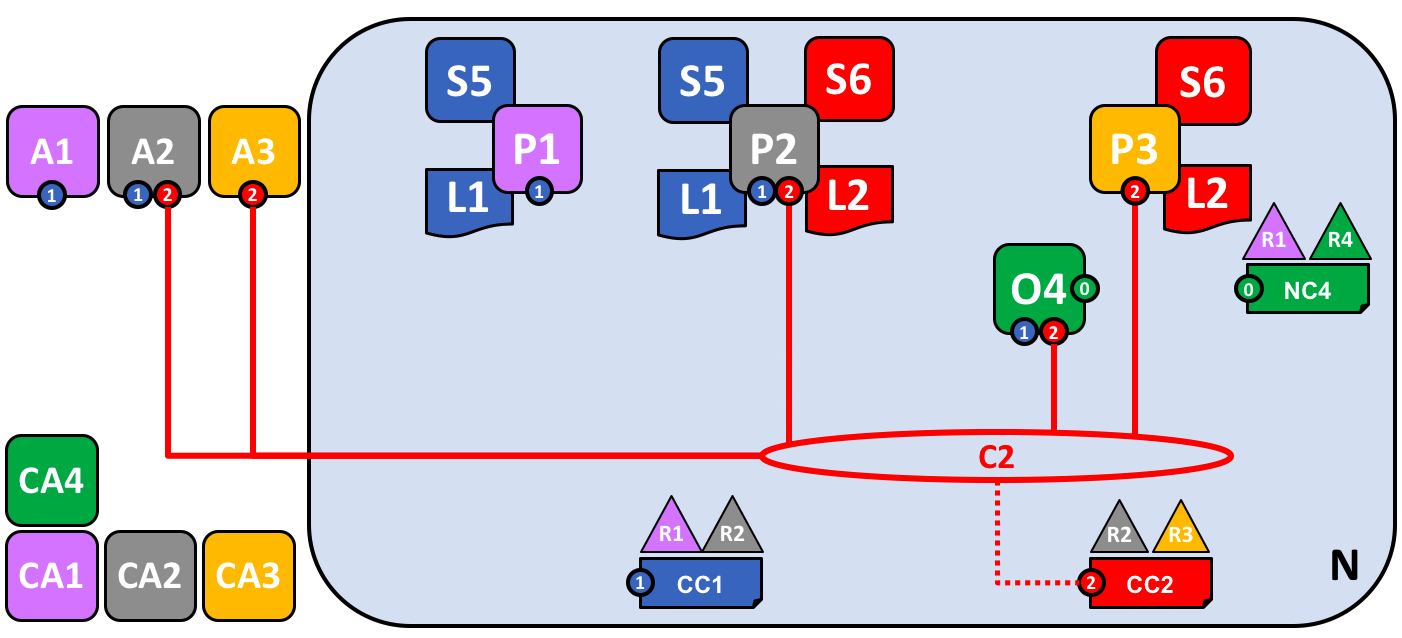
The diagram shows the facts relating to channels C1 and C2 in the network N as follows: Client applications A1 can use channel C1 for communication with peers P1 and P2, and ordering service O4; client application A2 can use channel C1 for communication with peers P1 and P2 and channel C2 for communication with peers P2 and P3 and ordering service O4; client application A3 can use channel C2 for communication with peer P3 and P2 and ordering service O4. Ordering service O4 can make use of the communication services of channels C1 and C2. Channel configuration CC1 applies to channel C1, CC2 applies to channel C2.
We can see that R2 is a special organization in the network, because it is the only organization that is a member of two application channels! It is able to transact with organization R1 on channel C1, while at the same time it can also transact with organization R3 on a different channel, C2.
Notice how peer node P2 has smart contract S5 installed for channel C1 and smart contract S6 installed for channel C2. Peer node P2 is a full member of both channels at the same time via different smart contracts for different ledgers.
This is a very powerful concept – channels provide both a mechanism for the separation of organizations, and a mechanism for collaboration between organizations. All the while, this infrastructure is provided by, and shared between, a set of independent organizations.
It is also important to note that peer node P2’s behaviour is controlled very differently depending upon the channel in which it is transacting. Specifically, the policies contained in channel configuration CC1 dictate the operations available to P2 when it is transacting in channel C1, whereas it is the policies in channel configuration CC2 that control P2’s behaviour in channel C2.
Again, this is desirable – R2 and R1 agreed the rules for channel C1, whereas R2 and R3 agreed the rules for channel C2. These rules were captured in the respective channel policies – they can and must be used by every component in a channel to enforce correct behaviour, as agreed.
Similarly, we can see that client application A2 is now able to transact on channels C1 and C2. And likewise, it too will be governed by the policies in the appropriate channel configurations. As an aside, note that client application A2 and peer node P2 are using a mixed visual vocabulary – both lines and connections. You can see that they are equivalent; they are visual synonyms.
The ordering service¶
The observant reader may notice that the ordering service node appears to be a centralized component; it was used to create the network initially, and connects to every channel in the network. Even though we added R1 and R4 to the network configuration policy NC4 which controls the orderer, the node was running on R4’s infrastructure. In a world of de-centralization, this looks wrong!
Don’t worry! Our example network showed the simplest ordering service configuration to help you understand the idea of a network administration point. In fact, the ordering service can itself too be completely de-centralized! We mentioned earlier that an ordering service could be comprised of many individual nodes owned by different organizations, so let’s see how that would be done in our sample network.
Let’s have a look at a more realistic ordering service node configuration:
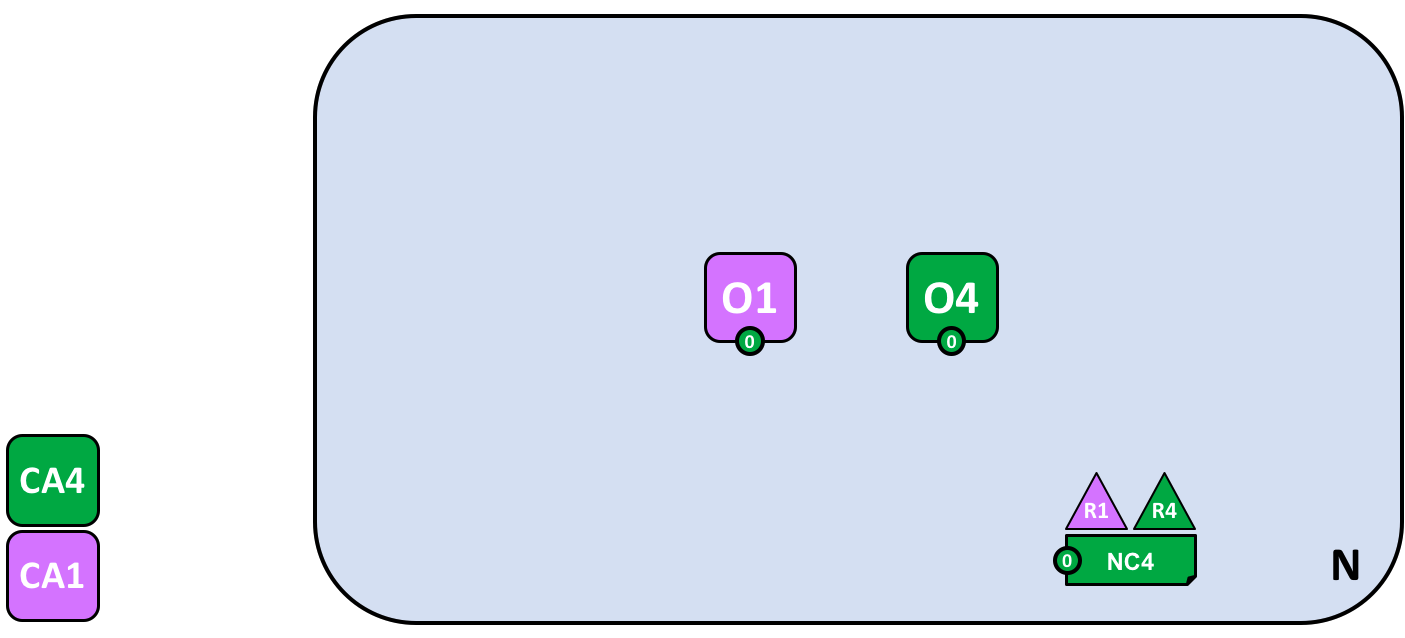
A multi-organization ordering service. The ordering service comprises ordering service nodes O1 and O4. O1 is provided by organization R1 and node O4 is provided by organization R4. The network configuration NC4 defines network resource permissions for actors from both organizations R1 and R4.
We can see that this ordering service completely de-centralized – it runs in organization R1 and it runs in organization R4. The network configuration policy, NC4, permits R1 and R4 equal rights over network resources. Client applications and peer nodes from organizations R1 and R4 can manage network resources by connecting to either node O1 or node O4, because both nodes behave the same way, as defined by the policies in network configuration NC4. In practice, actors from a particular organization tend to use infrastructure provided by their home organization, but that’s certainly not always the case.
De-centralized transaction distribution¶
As well as being the management point for the network, the ordering service also provides another key facility – it is the distribution point for transactions. The ordering service is the component which gathers endorsed transactions from applications and orders them into transaction blocks, which are subsequently distributed to every peer node in the channel. At each of these committing peers, transactions are recorded, whether valid or invalid, and their local copy of the ledger updated appropriately.
Notice how the ordering service node O4 performs a very different role for the channel C1 than it does for the network N. When acting at the channel level, O4’s role is to gather transactions and distribute blocks inside channel C1. It does this according to the policies defined in channel configuration CC1. In contrast, when acting at the network level, O4’s role is to provide a management point for network resources according to the policies defined in network configuration NC4. Notice again how these roles are defined by different policies within the channel and network configurations respectively. This should reinforce to you the importance of declarative policy based configuration in Hyperledger Fabric. Policies both define, and are used to control, the agreed behaviours by each and every member of a consortium.
We can see that the ordering service, like the other components in Hyperledger Fabric, is a fully de-centralized component. Whether acting as a network management point, or as a distributor of blocks in a channel, its nodes can be distributed as required throughout the multiple organizations in a network.
Changing policy¶
Throughout our exploration of the sample network, we’ve seen the importance of the policies to control the behaviour of the actors in the system. We’ve only discussed a few of the available policies, but there are many that can be declaratively defined to control every aspect of behaviour. These individual policies are discussed elsewhere in the documentation.
Most importantly of all, Hyperledger Fabric provides a uniquely powerful policy that allows network and channel administrators to manage policy change itself! The underlying philosophy is that policy change is a constant, whether it occurs within or between organizations, or whether it is imposed by external regulators. For example, new organizations may join a channel, or existing organizations may have their permissions increased or decreased. Let’s investigate a little more how change policy is implemented in Hyperledger Fabric.
They key point of understanding is that policy change is managed by a policy within the policy itself. The modification policy, or mod_policy for short, is a first class policy within a network or channel configuration that manages change. Let’s give two brief examples of how we’ve already used mod_policy to manage change in our network!
The first example was when the network was initially set up. At this time, only organization R4 was allowed to manage the network. In practice, this was achieved by making R4 the only organization defined in the network configuration NC4 with permissions to network resources. Moreover, the mod_policy for NC4 only mentioned organization R4 – only R4 was allowed to change this configuration.
We then evolved the network N to also allow organization R1 to administer the network. R4 did this by adding R1 to the policies for channel creation and consortium creation. Because of this change, R1 was able to define the consortia X1 and X2, and create the channels C1 and C2. R1 had equal administrative rights over the channel and consortium policies in the network configuration.
R4 however, could grant even more power over the network configuration to R1! R4 could add R1 to the mod_policy such that R1 would be able to manage change of the network policy too.
This second power is much more powerful than the first, because R1 now has full control over the network configuration NC4! This means that R1 can, in principle remove R4’s management rights from the network. In practice, R4 would configure the mod_policy such that R4 would need to also approve the change, or that all organizations in the mod_policy would have to approve the change. There’s lots of flexibility to make the mod_policy as sophisticated as it needs to be to support whatever change process is required.
This is mod_policy at work – it has allowed the graceful evolution of a basic configuration into a sophisticated one. All the time this has occurred with the agreement of all organization involved. The mod_policy behaves like every other policy inside a network or channel configuration; it defines a set of organizations that are allowed to change the mod_policy itself.
We’ve only scratched the surface of the power of policies and mod_policy in particular in this subsection. It is discussed at much more length in the policy topic, but for now let’s return to our finished network!
Network fully formed¶
Let’s recap what our network looks like using a consistent visual vocabulary. We’ve re-organized it slightly using our more compact visual syntax, because it better accommodates larger topologies:
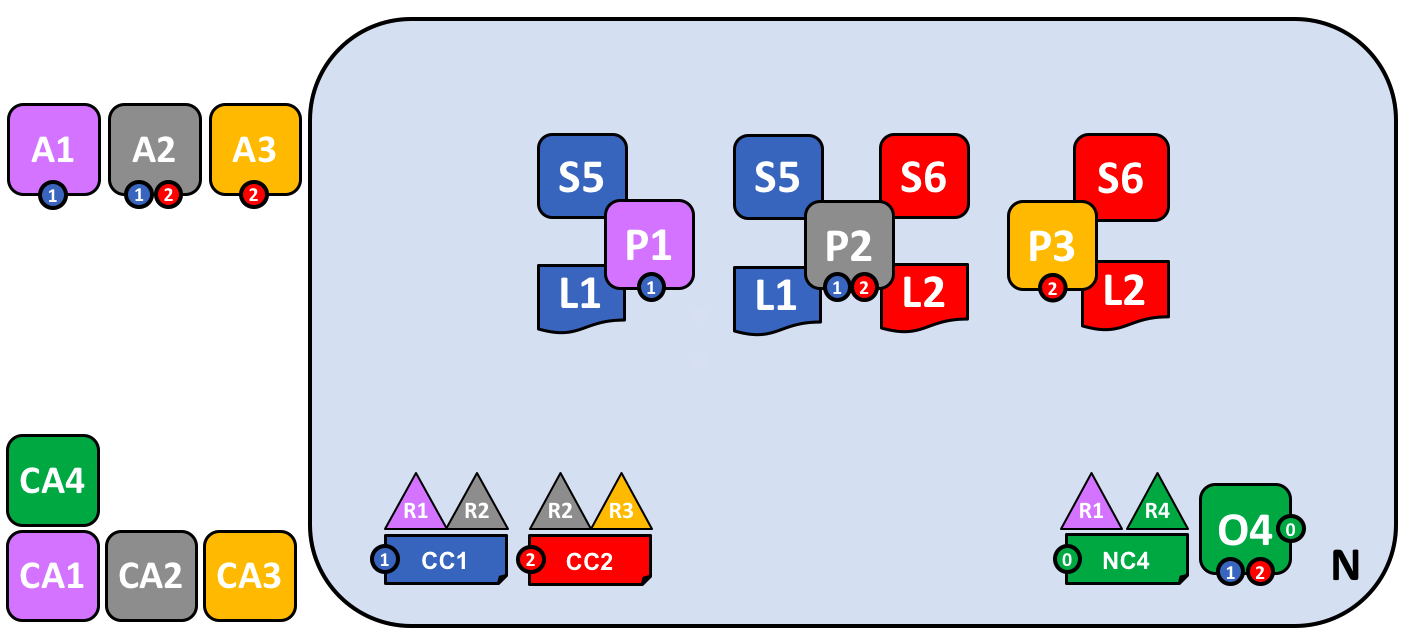
In this diagram we see that the Fabric blockchain network consists of two application channels and one ordering channel. The organizations R1 and R4 are responsible for the ordering channel, R1 and R2 are responsible for the blue application channel while R2 and R3 are responsible for the red application channel. Client applications A1 is an element of organization R1, and CA1 is its certificate authority. Note that peer P2 of organization R2 can use the communication facilities of the blue and the red application channel. Each application channel has its own channel configuration, in this case CC1 and CC2. The channel configuration of the system channel is part of the network configuration, NC4.
We’re at the end of our conceptual journey to build a sample Hyperledger Fabric blockchain network. We’ve created a four organization network with two channels and three peer nodes, with two smart contracts and an ordering service. It is supported by four certificate authorities. It provides ledger and smart contract services to three client applications, who can interact with it via the two channels. Take a moment to look through the details of the network in the diagram, and feel free to read back through the topic to reinforce your knowledge, or go to a more detailed topic.
Summary of network components¶
Here’s a quick summary of the network components we’ve discussed:
- Ledger. One per channel. Comprised of the Blockchain and the World state
- Smart contract (aka chaincode)
- Peer nodes
- Ordering service
- Channel
- Certificate Authority
Network summary¶
In this topic, we’ve seen how different organizations share their infrastructure to provide an integrated Hyperledger Fabric blockchain network. We’ve seen how the collective infrastructure can be organized into channels that provide private communications mechanisms that are independently managed. We’ve seen how actors such as client applications, administrators, peers and orderers are identified as being from different organizations by their use of certificates from their respective certificate authorities. And in turn, we’ve seen the importance of policy to define the agreed permissions that these organizational actors have over network and channel resources.